Naslednja arhitektura pojasnjuje potek oddaje poizvedbe v Hive.
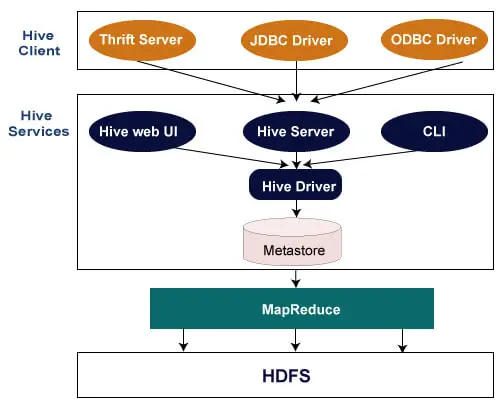
Hive Client
Hive omogoča pisanje aplikacij v različnih jezikih, vključno z Javo, Pythonom in C++. Podpira različne vrste strank, kot so:-
- Thrift Server – je medjezična platforma ponudnika storitev, ki služi zahtevam vseh tistih programskih jezikov, ki podpirajo Thrift.
- Gonilnik JDBC - Uporablja se za vzpostavitev povezave med panjem in aplikacijami Java. Gonilnik JDBC je prisoten v razredu org.apache.hadoop.hive.jdbc.HiveDriver.
- Gonilnik ODBC – omogoča aplikacijam, ki podpirajo protokol ODBC, da se povežejo s Hive.
Hive Storitve
Hive ponuja naslednje storitve:-
- Hive CLI – Hive CLI (vmesnik ukazne vrstice) je lupina, kjer lahko izvajamo poizvedbe in ukaze Hive.
- Spletni uporabniški vmesnik Hive - Spletni uporabniški vmesnik Hive je le alternativa Hive CLI. Zagotavlja spletni GUI za izvajanje poizvedb in ukazov Hive.
- Hive MetaStore - Je centralno skladišče, ki hrani vse informacije o strukturi različnih tabel in particij v skladišču. Vključuje tudi metapodatke stolpca in informacije o njegovem tipu, serializatorje in deserializatorje, ki se uporabljajo za branje in pisanje podatkov, ter ustrezne datoteke HDFS, kjer so shranjeni podatki.
- Hive Server – imenuje se Apache Thrift Server. Sprejme zahtevo različnih strank in jo posreduje Hive Driverju.
- Hive Driver - Prejema poizvedbe iz različnih virov, kot so spletni uporabniški vmesnik, CLI, Thrift in gonilnik JDBC/ODBC. Prenese poizvedbe v prevajalnik.
- Hive Compiler – Namen prevajalnika je razčleniti poizvedbo in izvesti semantično analizo različnih poizvedbenih blokov in izrazov. Izjave HiveQL pretvori v opravila MapReduce.
- Hive Execution Engine – Optimizer generira logični načrt v obliki DAG opravil za zmanjšanje zemljevidov in opravil HDFS. Na koncu izvajalni mehanizem izvede dohodne naloge po vrstnem redu njihovih odvisnosti.