BERT, akronim za dvosmerne predstavitve kodirnikov iz transformatorjev , stoji kot odprtokodna ogrodje strojnega učenja zasnovan za področje obdelava naravnega jezika (NLP) . To ogrodje, ki izvira iz leta 2018, so izdelali raziskovalci iz Google AI Language. Namen članka je raziskati arhitektura, delovanje in aplikacije BERT .
Kaj je BERT?
BERT (predstavitve dvosmernega kodirnika iz transformatorjev) uporablja transformatorsko nevronsko mrežo za razumevanje in ustvarjanje človeku podobnega jezika. BERT uporablja arhitekturo samo kodirnika. V originalu Transformatorska arhitektura , obstajajo tako kodirni kot dekodirni moduli. Odločitev za uporabo arhitekture samo kodirnika v BERT nakazuje primarni poudarek na razumevanju vhodnih zaporedij namesto na generiranju izhodnih zaporedij.
Dvosmerni pristop BERT
Tradicionalni jezikovni modeli obdelujejo besedilo zaporedno, od leve proti desni ali od desne proti levi. Ta metoda omejuje zavedanje modela na neposredni kontekst pred ciljno besedo. BERT uporablja dvosmerni pristop, ki upošteva tako levi kot desni kontekst besed v stavku, namesto da bi besedilo analiziral zaporedno, BERT gleda vse besede v stavku hkrati.
Primer: breg se nahaja na _______ reki.
V enosmernem modelu bi bilo razumevanje praznine močno odvisno od predhodnih besed in model bi morda imel težave pri razločevanju, ali se banka nanaša na finančno institucijo ali obrežje reke.
BERT, ki je dvosmeren, hkrati upošteva levi (obrežje se nahaja na) in desni kontekst (reke), kar omogoča bolj niansirano razumevanje. Razume, da je manjkajoča beseda verjetno povezana z geografsko lego banke, kar dokazuje kontekstualno bogastvo, ki ga prinaša dvosmerni pristop.
Predhodno usposabljanje in fina nastavitev
Model BERT je podvržen dvostopenjskemu procesu:
- Predhodno usposabljanje za velike količine neoznačenega besedila za učenje kontekstualnih vdelav.
- Natančna nastavitev označenih podatkov za posebne NLP naloge.
Predhodno usposabljanje o velikih podatkih
- BERT je vnaprej usposobljen za veliko količino neoznačenih besedilnih podatkov. Model se nauči kontekstualnih vdelav, ki so predstavitve besed, ki upoštevajo njihov okoliški kontekst v stavku.
- BERT opravlja različne nenadzorovane naloge pred usposabljanjem. Na primer, lahko se nauči predvideti manjkajoče besede v stavku (model maskiranega jezika ali naloga MLM), razumeti razmerje med dvema stavkoma ali predvideti naslednji stavek v paru.
Natančna nastavitev označenih podatkov
- Po fazi pred usposabljanjem se model BERT, oborožen s svojimi kontekstualnimi vstavitvami, nato natančno nastavi za specifične naloge obdelave naravnega jezika (NLP). Ta korak prilagodi model bolj ciljno usmerjenim aplikacijam s prilagajanjem njegovega splošnega razumevanja jezika niansam posamezne naloge.
- BERT je natančno nastavljen z uporabo označenih podatkov, specifičnih za zanimive naloge na nižji stopnji. Te naloge lahko vključujejo analizo razpoloženja, odgovarjanje na vprašanja, prepoznavanje imenovane entitete , ali katero koli drugo NLP aplikacijo. Parametri modela so prilagojeni tako, da optimizirajo njegovo delovanje za posebne zahteve obravnavane naloge.
Enotna arhitektura BERT-a omogoča, da se z minimalnimi spremembami prilagodi različnim nalogam na nižji stopnji, zaradi česar je vsestransko in zelo učinkovito orodje v razumevanje naravnega jezika in obdelavo.
Kako deluje BERT?
BERT je zasnovan za ustvarjanje jezikovnega modela, tako da se uporablja le mehanizem kodirnika. Zaporedje žetonov se napaja v kodirnik Transformer. Ti žetoni so najprej vdelani v vektorje in nato obdelani v nevronski mreži. Izhod je zaporedje vektorjev, od katerih vsak ustreza vhodnemu žetonu, ki zagotavlja kontekstualizirane predstavitve.
Pri usposabljanju jezikovnih modelov je definiranje cilja napovedi izziv. Mnogi modeli napovedujejo naslednjo besedo v zaporedju, kar je usmerjen pristop in lahko omeji učenje konteksta. BERT ta izziv obravnava z dvema inovativnima strategijama usposabljanja:
- Model maskiranega jezika (MLM)
- Predvidevanje naslednjega stavka (NSP)
1. Model maskiranega jezika (MLM)
V procesu predhodnega usposabljanja BERT je del besed v vsakem vhodnem zaporedju zamaskiran in model je usposobljen za predvidevanje izvirnih vrednosti teh zamaskiranih besed na podlagi konteksta, ki ga zagotavljajo okoliške besede.
Preprosto povedano,
- Maskirne besede: Preden se BERT uči iz stavkov, skrije nekaj besed (približno 15 %) in jih nadomesti s posebnim simbolom, kot je [MASK].
- Ugibanje skritih besed: BERT-ova naloga je ugotoviti, kaj so te skrite besede, tako da pogleda besede okoli njih. To je kot igra ugibanja, kje nekatere besede manjkajo, in BERT poskuša zapolniti praznine.
- Kako se BERT uči:
- BERT svojemu učnemu sistemu doda posebno plast, da lahko ugiba. Nato preveri, kako blizu so njegove ugibanje dejanskim skritim besedam.
- To naredi tako, da svoja ugibanja pretvori v verjetnosti in reče: Mislim, da je ta beseda X, in tako sem prepričan o tem.
- Posebna pozornost do skritih besed
- BERT-ov glavni poudarek med usposabljanjem je na pravilnosti teh skritih besed. Manj skrbi za napovedovanje besed, ki niso skrite.
- To je zato, ker je pravi izziv ugotoviti manjkajoče dele in ta strategija pomaga BERT-u, da postane res dober pri razumevanju pomena in konteksta besed.
V tehničnem smislu,
- BERT doda klasifikacijsko plast na vrh izhoda iz kodirnika. Ta plast je ključnega pomena za napovedovanje zamaskiranih besed.
- Izhodni vektorji iz klasifikacijske plasti se pomnožijo z vdelano matriko in jih pretvorijo v dimenzijo besedišča. Ta korak pomaga uskladiti predvidene predstavitve s prostorom besedišča.
- Verjetnost vsake besede v besednjaku se izračuna z uporabo Funkcija aktivacije SoftMax . Ta korak generira porazdelitev verjetnosti po celotnem besedišču za vsako maskirano pozicijo.
- Funkcija izgube, uporabljena med usposabljanjem, upošteva samo napoved prikritih vrednosti. Model je kaznovan zaradi odstopanja med njegovimi napovedmi in dejanskimi vrednostmi maskiranih besed.
- Model konvergira počasneje kot usmerjeni modeli. To je zato, ker se BERT med usposabljanjem ukvarja le z napovedovanjem zamaskiranih vrednosti in ignorira napovedovanje nezamaskiranih besed. Povečano zavedanje konteksta, doseženo s to strategijo, kompenzira počasnejšo konvergenco.
2. Napoved naslednjega stavka (NSP)
BERT napove, ali je drugi stavek povezan s prvim. To se naredi tako, da se izhod žetona [CLS] pretvori v vektor v obliki 2×1 z uporabo klasifikacijske plasti in nato z uporabo SoftMax izračuna verjetnost, ali drugi stavek sledi prvemu.
- V procesu usposabljanja se BERT nauči razumeti razmerje med pari stavkov in predvideti, ali drugi stavek sledi prvemu v izvirnem dokumentu.
- 50 % vnosnih parov ima drugi stavek kot naslednji stavek v izvirnem dokumentu, ostalih 50 % pa ima naključno izbran stavek.
- Za pomoč modelu pri razlikovanju med povezanimi in nepovezanimi stavčnimi pari. Vnos se obdela pred vnosom modela:
- Žeton [CLS] je vstavljen na začetku prvega stavka, žeton [SEP] pa je dodan na koncu vsakega stavka.
- Vsakemu žetonu je dodana vdelava stavka, ki označuje stavek A ali stavek B.
- Pozicijska vdelava označuje položaj vsakega žetona v zaporedju.
- BERT napove, ali je drugi stavek povezan s prvim. To se naredi tako, da se izhod žetona [CLS] pretvori v vektor v obliki 2×1 z uporabo klasifikacijske plasti in nato z uporabo SoftMax izračuna verjetnost, ali drugi stavek sledi prvemu.
Med usposabljanjem modela BERT se Masked LM in Next Sentence Prediction usposabljata skupaj. Cilj modela je čim bolj zmanjšati kombinirano funkcijo izgube zamaskiranega LM in predvidevanja naslednjega stavka, kar vodi do robustnega jezikovnega modela z izboljšanimi zmogljivostmi pri razumevanju konteksta v stavkih in odnosov med stavki.
Zakaj trenirati Masked LM in Next Sentence Prediction skupaj?
Masked LM pomaga BERTU razumeti kontekst v stavku in Napoved naslednjega stavka pomaga BERTU dojeti povezavo ali odnos med pari stavkov. Zato skupno usposabljanje obeh strategij zagotavlja, da se BERT nauči širokega in celovitega razumevanja jezika, pri čemer zajame tako podrobnosti v stavkih kot tok med stavki.
Arhitektura BERT
Arhitektura BERT je večplastni dvosmerni transformatorski kodirnik, ki je precej podoben modelu transformatorja. Transformatorska arhitektura je kodirno-dekodirno omrežje, ki uporablja samopozornost na strani kodirnika in pozornost na strani dekoderja.
- BERTBAZAima 1 2 plasti v skladu Encoder medtem ko BERTVELIKima 24 plasti v skladu Encoder . To je več kot arhitektura Transformerja, opisana v izvirnem dokumentu ( 6 plasti kodirnika ).
- Arhitekturi BERT (BASE in LARGE) imata tudi večja omrežja s posredovanjem (768 oziroma 1024 skritih enot) in več pozornosti glave (12 oziroma 16) kot arhitektura Transformerja, predlagana v izvirnem dokumentu. Vsebuje 512 skritih enot in 8 glav pozornosti .
- BERTBAZAvsebuje 110M parametrov, medtem ko BERTVELIKima 340M parametrov.

BERT BASE in BERT LARGE arhitektura.
Ta model zajema CLS najprej kot vnos žeton, nato mu sledi zaporedje besed kot vnos. Tu je CLS klasifikacijski žeton. Nato posreduje vhod zgornjim slojem. Vsak sloj velja samopozornost in posreduje rezultat skozi omrežje za naprej, nato pa ga preda naslednjemu kodirniku. Model izpiše vektor skrite velikosti ( 768 za BERT BASE). Če želimo iz tega modela izpisati klasifikator, lahko vzamemo izhod, ki ustreza žetonu CLS.
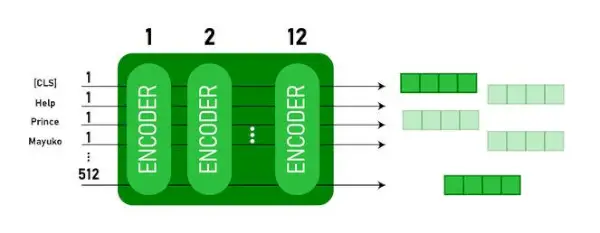
Izhod BERT kot vdelave
Zdaj lahko ta usposobljeni vektor uporabimo za izvajanje številnih nalog, kot so klasifikacija, prevajanje itd. Na primer, papir dosega odlične rezultate samo z uporabo ene plasti Zivcno omrezje na modelu BERT pri klasifikacijski nalogi.
Kako uporabiti model BERT v NLP?
BERT se lahko uporablja za različne naloge obdelave naravnega jezika (NLP), kot so:
1. Naloga za razvrščanje
- BERT se lahko uporablja za naloge razvrščanja, kot je npr analiza razpoloženja , cilj je razvrstiti besedilo v različne kategorije (pozitivno/negativno/nevtralno), lahko BERT uporabite tako, da dodate klasifikacijsko plast na vrh izhoda Transformerja za žeton [CLS].
- Žeton [CLS] predstavlja združene informacije iz celotnega vhodnega zaporedja. Ta združena predstavitev se lahko nato uporabi kot vhod za klasifikacijsko plast za izdelavo napovedi za specifično nalogo.
2. Odgovarjanje na vprašanja
- Pri nalogah z odgovarjanjem na vprašanja, kjer mora model poiskati in označiti odgovor v danem zaporedju besedila, se lahko BERT usposobi za ta namen.
- BERT se usposobi za odgovarjanje na vprašanja z učenjem dveh dodatnih vektorjev, ki označujeta začetek in konec odgovora. Med usposabljanjem model dobi vprašanja in ustrezne odlomke ter se nauči predvideti začetni in končni položaj odgovora v odlomku.
3. Prepoznavanje imenovane entitete (NER)
- BERT je mogoče uporabiti za NER, kjer je cilj identificirati in razvrstiti entitete (npr. Oseba, Organizacija, Datum) v besedilnem zaporedju.
- Model NER, ki temelji na BERT, se usposablja tako, da se izhodni vektor vsakega žetona vzame iz transformatorja in se vnese v klasifikacijsko plast. Plast predvideva imenovano oznako entitete za vsak žeton, ki označuje vrsto entitete, ki jo predstavlja.
Kako tokenizirati in kodirati besedilo z uporabo BERT?
Za tokeniziranje in kodiranje besedila z uporabo BERT bomo uporabili knjižnico 'transformer' v Pythonu.
Ukaz za namestitev transformatorjev:
!pip install transformers>
- Vnaprej usposobljeno tokenizacijo BERT bomo naložili z velikimi črkami in z uporabo BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(besedilo) tokenizira vhodno besedilo in ga pretvori v zaporedje ID-jev žetonov.
- natisni (ID-ji žetonov:, kodiranje) natisne ID-je žetonov, pridobljene po kodiranju.
- tokenizer.convert_ids_to_tokens(kodiranje) pretvori ID-je žetonov nazaj v njihove ustrezne žetone.
- natisni (žetoni:, žetoni) natisne žetone, pridobljene po pretvorbi ID-jev žetonov
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Izhod:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> The tokenizer.encode metoda doda posebnost [CLS] – razvrstitev in [SEP] – ločilo žetonov na začetku in koncu kodiranega zaporedja.
Uporaba BERT
BERT se uporablja za:
- Predstavitev besedila: BERT se uporablja za ustvarjanje besednih vdelav ali predstavitev besed v stavku.
- Prepoznavanje imenovane entitete (NER) : BERT je mogoče natančno nastaviti za naloge prepoznavanja poimenovanih entitet, kjer je cilj identificirati entitete, kot so imena ljudi, organizacije, lokacije itd., v danem besedilu.
- Klasifikacija besedila: BERT se pogosto uporablja za naloge klasifikacije besedil, vključno z analizo razpoloženja, zaznavanjem neželene pošte in kategorizacijo tem. Dokazal je odlično zmogljivost pri razumevanju in razvrščanju konteksta besedilnih podatkov.
- Sistemi za odgovore na vprašanja: BERT je bil uporabljen za sisteme odgovorov na vprašanja, kjer je model usposobljen za razumevanje konteksta vprašanja in zagotavljanje ustreznih odgovorov. To je še posebej uporabno za naloge, kot je bralno razumevanje.
- Strojno prevajanje: Kontekstualne vdelave BERT-a je mogoče uporabiti za izboljšanje sistemov za strojno prevajanje. Model zajame nianse jezika, ki so ključne za natančen prevod.
- Povzetek besedila: BERT se lahko uporablja za abstraktno povzemanje besedil, kjer model ustvari jedrnate in smiselne povzetke daljših besedil z razumevanjem konteksta in semantike.
- Pogovorni AI: BERT je zaposlen pri gradnji pogovornih sistemov umetne inteligence, kot so klepetalni roboti, virtualni pomočniki in sistemi za dialog. Zaradi njegove zmožnosti razumevanja konteksta je učinkovit pri razumevanju in ustvarjanju odzivov naravnega jezika.
- Semantična podobnost: Vdelave BERT se lahko uporabljajo za merjenje semantične podobnosti med stavki ali dokumenti. To je dragoceno pri nalogah, kot so odkrivanje dvojnikov, prepoznavanje parafraze in iskanje informacij.
BERT proti GPT
Razlika med BERT in GPT je naslednja:
| BERT | GPT | |
|---|---|---|
| Arhitektura | BERT je zasnovan za učenje dvosmernega predstavljanja. Uporablja cilj maskiranega jezikovnega modela, kjer predvideva manjkajoče besede v stavku na podlagi levega in desnega konteksta. | GPT je po drugi strani zasnovan za generativno jezikovno modeliranje. Predvidi naslednjo besedo v stavku glede na predhodni kontekst z uporabo enosmernega avtoregresivnega pristopa. |
| Cilji pred usposabljanjem | BERT je vnaprej usposobljen z uporabo cilja maskiranega jezikovnega modela in predvidevanja naslednjega stavka. Osredotoča se na zajem dvosmernega konteksta in razumevanje odnosov med besedami v stavku. | GPT je vnaprej usposobljen za predvidevanje naslednje besede v stavku, kar spodbuja model, da se nauči koherentne predstavitve jezika in ustvari kontekstualno relevantna zaporedja. |
| Razumevanje konteksta | BERT je učinkovit za naloge, ki zahtevajo globoko razumevanje konteksta in odnosov v stavku, kot je razvrščanje besedila, prepoznavanje imenovanih entitet in odgovarjanje na vprašanja. | GPT je močan pri ustvarjanju koherentnega in kontekstualno ustreznega besedila. Pogosto se uporablja pri ustvarjalnih nalogah, dialoških sistemih in nalogah, ki zahtevajo ustvarjanje sekvenc naravnega jezika. |
| Vrste nalog in primeri uporabe
| Običajno se uporablja pri nalogah, kot so klasifikacija besedila, prepoznavanje imenovanih entitet, analiza čustev in odgovarjanje na vprašanja. | Uporablja se za naloge, kot so ustvarjanje besedila, sistemi dialogov, povzemanje in kreativno pisanje. |
| Natančna nastavitev v primerjavi z nekajkratnim učenjem | BERT je pogosto natančno nastavljen na določenih nadaljnjih nalogah z označenimi podatki, da svoje vnaprej usposobljene predstavitve prilagodi trenutni nalogi. | GPT je zasnovan za izvajanje učenja v nekaj korakih, kjer se lahko posploši na nove naloge z minimalnimi podatki o usposabljanju, specifičnimi za nalogo. |
Preverite tudi:
- Klasifikacija čustev z uporabo BERT
- Kako ustvariti vdelavo besed s pomočjo BERT?
- Model BART za samodejno dokončanje besedila v NLP
- Klasifikacija strupenih komentarjev z uporabo BERT
- Predvidevanje naslednjega stavka z uporabo BERT
Pogosto zastavljena vprašanja (FAQ)
V. Za kaj se uporablja BERT?
BERT se uporablja za izvajanje nalog NLP, kot so predstavitev besedila, prepoznavanje poimenovanih entitet, klasifikacija besedil, sistemi vprašanj in odgovorov, strojno prevajanje, povzemanje besedila itd.
V. Kakšne so prednosti modela BERT?
Jezikovni model BERT izstopa zaradi obsežnega predhodnega usposabljanja v več jezikih, ki ponuja široko jezikovno pokritost v primerjavi z drugimi modeli. Zaradi tega je BERT še posebej ugoden za projekte, ki ne temeljijo na angleščini, saj zagotavlja robustne kontekstualne predstavitve in semantično razumevanje v različnih jezikih, kar povečuje njegovo vsestranskost v večjezičnih aplikacijah.
V. Kako BERT deluje pri analizi razpoloženja?
BERT je odličen pri analizi razpoloženja, saj izkorišča učenje dvosmerne predstavitve za zajemanje kontekstualnih odtenkov, semantičnih pomenov in sintaktičnih struktur v danem besedilu. To omogoča BERT-u, da razume razpoloženje, izraženo v stavku, z upoštevanjem odnosov med besedami, kar ima za posledico zelo učinkovite rezultate analize razpoloženja.
neurejeno prečkanje binarnega drevesa
V. Ali Google temelji na BERT?
BERT in RankBrain so sestavni deli Googlovega iskalnega algoritma za obdelavo poizvedb in vsebine spletnih strani za boljše razumevanje in izboljšanje rezultatov iskanja.