Neobveščeno iskanje je razred splošnih iskalnih algoritmov, ki delujejo na način surove sile. Neobveščeni iskalni algoritmi nimajo dodatnih informacij o stanju ali iskalnem prostoru, razen o tem, kako prečkati drevo, zato se imenuje tudi slepo iskanje.
Sledijo različne vrste neinformiranih iskalnih algoritmov:
1. Iskanje v širino:
- Iskanje v širino je najpogostejša iskalna strategija za prečkanje drevesa ali grafa. Ta algoritem išče po drevesu ali grafu po širini, zato se imenuje iskanje po širini.
- Algoritem BFS začne iskati od korenskega vozlišča drevesa in razširi vsa naslednja vozlišča na trenutni ravni, preden se premakne na vozlišča naslednje ravni.
- Algoritem iskanja v širino je primer algoritma iskanja po splošnem grafu.
- Iskanje v širino, izvedeno s podatkovno strukturo čakalne vrste FIFO.
Prednosti:
- BFS bo ponudil rešitev, če obstaja.
- Če obstaja več kot ena rešitev za dano težavo, bo BFS zagotovil minimalno rešitev, ki zahteva najmanjše število korakov.
Slabosti:
- Potrebuje veliko pomnilnika, saj je treba vsako raven drevesa shraniti v pomnilnik, da se razširi naslednja raven.
- BFS potrebuje veliko časa, če je rešitev daleč od korenskega vozlišča.
primer:
V spodnji drevesni strukturi smo prikazali prečkanje drevesa z uporabo algoritma BFS od korenskega vozlišča S do ciljnega vozlišča K. Iskalni algoritem BFS prečka po plasteh, tako da bo sledil poti, ki jo prikazuje pikčasta puščica, in prehojena pot bo:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
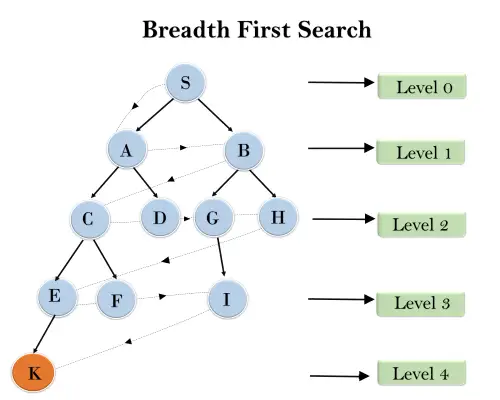
Časovna zapletenost: Časovno kompleksnost algoritma BFS je mogoče pridobiti s številom vozlišč, prevoženih v BFS do najplitejšega vozlišča. Pri čemer je d = globina najplitve rešitve in je b vozlišče v vsakem stanju.
T (b) = 1+b2+b3+......+ bd= O (bd)
kako vedeti, ali vas je nekdo blokiral na androidu
Kompleksnost prostora: Prostorska kompleksnost algoritma BFS je podana z velikostjo pomnilnika meje, ki je O(bd).
Popolnost: BFS je končan, kar pomeni, da če je najplitvejše ciljno vozlišče na neki končni globini, bo BFS našel rešitev.
Optimalnost: BFS je optimalen, če je cena poti nepadajoča funkcija globine vozlišča.
2. Iskanje v globino
- Iskanje najprej v globino je rekurziven algoritem za prečkanje drevesne ali grafične podatkovne strukture.
- Imenuje se iskanje najprej v globino, ker se začne od korenskega vozlišča in sledi vsaki poti do njenega največjega globinskega vozlišča, preden se premakne na naslednjo pot.
- DFS za svojo implementacijo uporablja podatkovno strukturo sklada.
- Postopek algoritma DFS je podoben algoritmu BFS.
Opomba: Sledenje nazaj je tehnika algoritma za iskanje vseh možnih rešitev z uporabo rekurzije.
Prednost:
- DFS zahteva zelo manj pomnilnika, saj mora shraniti le sklad vozlišč na poti od korenskega vozlišča do trenutnega vozlišča.
- Za doseganje ciljnega vozlišča potrebuje manj časa kot algoritem BFS (če prečka po pravi poti).
Slabost:
- Obstaja možnost, da se številna stanja ponavljajo, vendar ni nobenega zagotovila, da bomo našli rešitev.
- Algoritem DFS uporablja globoko iskanje in včasih gre lahko v neskončno zanko.
primer:
V spodnjem iskalnem drevesu smo prikazali potek iskanja najprej v globino in bo sledil vrstnemu redu kot:
Korensko vozlišče--->Levo vozlišče ----> desno vozlišče.
Začel bo iskati od korenskega vozlišča S in prečkal A, nato B, nato D in E, po prečkanju E se bo vrnil v drevo, ker E nima drugega naslednika in ciljno vozlišče še vedno ni najdeno. Po povratnem sledenju bo prečkal vozlišče C in nato G, tu pa se bo končal, ko je našel ciljno vozlišče.

Popolnost: Iskalni algoritem DFS je popoln znotraj končnega prostora stanj, saj bo razširil vsako vozlišče znotraj omejenega iskalnega drevesa.
Časovna zapletenost: Časovna kompleksnost DFS bo enakovredna vozlišču, ki ga prečka algoritem. Podaja ga:
T(n)= 1+ n2+ n3+.........+ nm=O(nm)
Kjer je m = največja globina katerega koli vozlišča in je lahko veliko večja od d (najmanjša globina rešitve)
Kompleksnost prostora: Algoritem DFS mora shraniti samo eno pot od korenskega vozlišča, zato je prostorska kompleksnost DFS enakovredna velikosti obrobnega niza, ki je O(bm) .
Optimalno: Iskalni algoritem DFS ni optimalen, saj lahko ustvari veliko število korakov ali visoke stroške za doseganje ciljnega vozlišča.
3. Algoritem iskanja z omejeno globino:
Algoritem iskanja z omejeno globino je podoben iskanju najprej v globino z vnaprej določeno mejo. Iskanje z omejeno globino lahko odpravi pomanjkljivost neskončne poti pri iskanju najprej v globino. V tem algoritmu bo vozlišče na meji globine obravnavano, kot da nima nadaljnjih vozlišč naslednikov.
Iskanje z omejeno globino je mogoče prekiniti z dvema pogojema neuspeha:
- Standardna vrednost napake: označuje, da težava nima rešitve.
- Mejna vrednost neuspeha: Ne opredeljuje nobene rešitve za problem znotraj dane omejitve globine.
Prednosti:
Iskanje z omejeno globino je učinkovito pri pomnilniku.
Slabosti:
- Globinsko omejeno iskanje ima tudi pomanjkljivost nepopolnosti.
- Morda ni optimalno, če ima problem več kot eno rešitev.
primer:

Popolnost: Algoritem iskanja DLS je dokončan, če je rešitev nad mejo globine.
Časovna zapletenost: Časovna zahtevnost algoritma DLS je O(bℓ) .
Kompleksnost prostora: Prostorska kompleksnost algoritma DLS je O (b�ℓ) .
Optimalno: Iskanje z omejeno globino lahko obravnavamo kot poseben primer DFS in tudi ni optimalno, tudi če je ℓ>d.
4. Algoritem iskanja po enotni ceni:
Iskanje po enotni ceni je iskalni algoritem, ki se uporablja za prečkanje uteženega drevesa ali grafa. Ta algoritem pride v poštev, ko je za vsak rob na voljo drugačna cena. Primarni cilj iskanja z enotnimi stroški je najti pot do ciljnega vozlišča, ki ima najnižje kumulativne stroške. Iskanje po enotnih stroških razširi vozlišča glede na njihove stroške poti iz korenskega vozlišča. Uporablja se lahko za reševanje katerega koli grafa/drevesa, kjer so potrebni optimalni stroški. Algoritem iskanja po enotni ceni izvaja prednostna čakalna vrsta. Največjo prednost daje najnižjim kumulativnim stroškom. Enotno iskanje stroškov je enakovredno algoritmu BFS, če so stroški poti vseh robov enaki.
Prednosti:
- Enotno iskanje stroškov je optimalno, ker je pri vsakem stanju izbrana pot z najmanjšimi stroški.
Slabosti:
- Ne zanima ga število korakov, vključenih v iskanje, skrbijo ga le stroški poti. Zaradi tega se lahko ta algoritem zatakne v neskončni zanki.
primer:

Popolnost:
Iskanje po enotnih stroških je končano, na primer, če obstaja rešitev, jo bo UCS našel.
Časovna zapletenost:
Naj C* je Strošek optimalne rešitve , in e je vsak korak, da se približamo ciljnemu vozlišču. Potem je število korakov = C*/ε+1. Tukaj smo vzeli +1, saj začnemo od stanja 0 in končamo do C*/ε.
Zato je najslabša časovna zapletenost iskanja po enotnih stroških O(b1 + [C*/e])/ .
Kompleksnost prostora:
Ista logika velja za kompleksnost prostora, tako da je najslabši možni prostor kompleksnosti iskanja po enotni ceni O(b1 + [C*/e]) .
Optimalno:
Iskanje po enotni ceni je vedno optimalno, saj izbere le pot z najnižjo ceno poti.
5. Ponavljajoče se iskanje po globini:
Algoritem iterativnega poglabljanja je kombinacija algoritmov DFS in BFS. Ta iskalni algoritem poišče najboljšo mejo globine in to stori tako, da mejo postopoma povečuje, dokler ni najden cilj.
Ta algoritem izvaja iskanje najprej v globino do določene 'meje globine' in po vsaki ponovitvi povečuje mejo globine, dokler ni najdeno ciljno vozlišče.
Ta algoritem iskanja združuje prednosti hitrega iskanja v širino in učinkovitost pomnilnika iskanja v globino.
programski vzorci java
Algoritem iterativnega iskanja je uporaben za neinformirano iskanje, ko je iskalni prostor velik in globina ciljnega vozlišča ni znana.
Prednosti:
- Združuje prednosti iskalnega algoritma BFS in DFS v smislu hitrega iskanja in učinkovitosti pomnilnika.
Slabosti:
- Glavna pomanjkljivost IDDFS je, da ponavlja vse delo prejšnje faze.
primer:
Naslednja drevesna struktura prikazuje iterativno poglabljanje v globino. Algoritem IDDFS izvaja različne iteracije, dokler ne najde ciljnega vozlišča. Ponovitev, ki jo izvede algoritem, je podana kot:

1. ponovitev-----> A
2. ponovitev----> A, B, C
3. ponovitev------>A, B, D, E, C, F, G
4. ponovitev------>A, B, D, H, I, E, C, F, K, G
V četrti ponovitvi bo algoritem našel ciljno vozlišče.
Popolnost:
Ta algoritem je popoln, če je faktor razvejanja končen.
Časovna zapletenost:
Recimo, da je b faktor razvejanja in globina d, potem je najslabša časovna kompleksnost O(bd) .
Kompleksnost prostora:
Prostorska kompleksnost IDDFS bo O(bd) .
Optimalno:
Algoritem IDDFS je optimalen, če je cena poti nepadajoča funkcija globine vozlišča.
6. Algoritem dvosmernega iskanja:
Dvosmerni iskalni algoritem izvaja dve istočasni iskanji, eno iz začetnega stanja, imenovano iskanje naprej, drugo iz ciljnega vozlišča, imenovano iskanje nazaj, da najde ciljno vozlišče. Dvosmerno iskanje nadomešča en sam iskalni graf z dvema majhnima podgrafoma, v katerih eden začne iskanje od začetne točke, drugi pa od ciljne točke. Iskanje se ustavi, ko se ta dva grafa sekata.
Dvosmerno iskanje lahko uporablja iskalne tehnike, kot so BFS, DFS, DLS itd.
Prednosti:
- Dvosmerno iskanje je hitro.
- Dvosmerno iskanje zahteva manj pomnilnika
Slabosti:
- Implementacija dvosmernega iskalnega drevesa je težavna.
primer:
V spodnjem iskalnem drevesu je uporabljen dvosmerni iskalni algoritem. Ta algoritem razdeli en graf/drevo na dva podgrafa. Začne se premikati od vozlišča 1 v smeri naprej in se začne od ciljnega vozlišča 16 v smeri nazaj.
Algoritem se konča na vozlišču 9, kjer se srečata dve iskanji.

Popolnost: Dvosmerno iskanje je popolno, če pri obeh iskanjih uporabimo BFS.
Časovna zapletenost: Časovna zahtevnost dvosmernega iskanja z BFS je O(bd) .
Kompleksnost prostora: Prostorska kompleksnost dvosmernega iskanja je O(bd) .
Optimalno: Dvosmerno iskanje je optimalno.