Ključna beseda IDENTITY je lastnost v strežniku SQL Server. Ko je stolpec tabele definiran z lastnostjo identitete, bo njegova vrednost samodejno ustvarjena inkrementalna vrednost . To vrednost samodejno ustvari strežnik. Zato ne moremo ročno vnesti vrednosti v stolpec identitete kot uporabnik. Če torej stolpec označimo kot identiteto, ga bo SQL Server zapolnil na način samodejnega povečanja.
Sintaksa
Sledi sintaksa za ponazoritev uporabe lastnosti IDENTITY v strežniku SQL Server:
IDENTITY[(seed, increment)]
Zgornji sintaksni parametri so razloženi spodaj:
Razumejmo ta koncept s preprostim primerom.
Recimo, da imamo ' študent ' mizo, in želimo Študent ID ki se ustvari samodejno. Imamo začetna študentska izkaznica 10 in ga želite povečati za 1 z vsakim novim ID-jem. V tem scenariju je treba definirati naslednje vrednosti.
seme: 10
Povečanje: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
OPOMBA: Samo en identifikacijski stolpec je dovoljen na tabelo v strežniku SQL Server.
Primer IDENTITETE strežnika SQL
Razumejmo, kako lahko uporabimo lastnost identitete v tabeli. Lastnost identitete v stolpcu je mogoče nastaviti, ko je ustvarjena nova tabela ali potem, ko je bila ustvarjena. Tukaj si bomo ogledali oba primera s primeri.
Lastnost IDENTITY z novo tabelo
Naslednji stavek bo ustvaril novo tabelo z lastnostjo identitete v podani bazi podatkov:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Nato bomo v to tabelo vstavili novo vrstico z IZHOD klavzula za ogled samodejno ustvarjenega ID-ja osebe:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
Izvedba te poizvedbe bo prikazala spodnji rezultat:
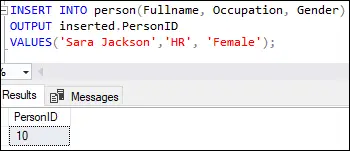
Ta izhod kaže, da je bila prva vrstica vstavljena z vrednostjo deset v ID osebe kot je določeno v stolpcu identitete definicije tabele.
Vstavimo še eno vrstico v tabela oseb kot spodaj:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Ta poizvedba bo vrnila naslednje rezultate:

Ta izhod kaže, da je bila druga vrstica vstavljena z vrednostjo 11 in tretja vrstica z vrednostjo 12 v stolpcu PersonID.
Lastnost IDENTITY z obstoječo tabelo
Ta koncept bomo razložili tako, da najprej izbrišemo zgornjo tabelo in ju ustvarimo brez lastnosti identitete. Izvedite spodnji stavek, da spustite tabelo:
DROP TABLE person;
Nato bomo ustvarili tabelo s spodnjo poizvedbo:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Če želimo v obstoječo tabelo dodati nov stolpec z lastnostjo identitete, moramo uporabiti ukaz ALTER. Spodnja poizvedba bo dodala ID osebe kot stolpec identitete v tabeli oseb:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Izrecno dodajanje vrednosti v stolpec identitete
Če v zgornjo tabelo dodamo novo vrstico tako, da izrecno podamo vrednost stolpca identitete, bo SQL Server izdal napako. Oglejte si spodnjo poizvedbo:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
Pri izvajanju te poizvedbe se prikaže naslednja napaka:

Če želite eksplicitno vstaviti vrednost stolpca identitete, moramo najprej nastaviti vrednost IDENTITY_INSERT na ON. Nato izvedite operacijo vstavljanja, da dodate novo vrstico v tabelo in nato nastavite vrednost IDENTITY_INSERT na IZKLOP. Oglejte si spodnji kodni skript:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT ON omogoča uporabnikom, da vnesejo podatke v stolpce z identiteto, medtem ko IDENTITY_INSERT OFF jim preprečuje dodajanje vrednosti v ta stolpec.
Izvajanje kodnega skripta bo prikazalo spodnji rezultat, kjer lahko vidimo, da je PersonID z vrednostjo 14 uspešno vstavljen.

Funkcija IDENTITETE
SQL Server ponuja nekaj funkcij identitete za delo s stolpci IDENTITY v tabeli. Te funkcije identitete so navedene spodaj:
- Funkcija @@IDENTITY
- Funkcija SCOPE_IDENTITY().
- Funkcija IDENT_CURRENT
- Funkcija IDENTITETE
Oglejmo si funkcije IDENTITY z nekaj primeri.
Funkcija @@IDENTITY
@@IDENTITY je sistemsko definirana funkcija, ki prikaže zadnjo vrednost identitete (največja uporabljena vrednost identitete), ustvarjena v tabeli za stolpec IDENTITY v isti seji. Ta funkcijski stolpec vrne vrednost identitete, ki jo ustvari stavek po vstavitvi novega vnosa v tabelo. Vrne a NIČ vrednost, ko izvedemo poizvedbo, ki ne ustvari vrednosti IDENTITY. Vedno deluje v okviru trenutne seje. Ni ga mogoče uporabljati na daljavo.
Primer
Recimo, da je trenutna največja vrednost identitete v tabeli oseb 13. Zdaj bomo v isti seji dodali en zapis, ki poveča vrednost identitete za eno. Nato bomo uporabili funkcijo @@IDENTITY, da pridobimo zadnjo vrednost identitete, ustvarjeno v isti seji.
Tukaj je celoten skript kode:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
Izvajanje skripta bo vrnilo naslednji rezultat, kjer lahko vidimo, da je največja uporabljena vrednost identitete 14.

Funkcija SCOPE_IDENTITY().
SCOPE_IDENTITY() je sistemsko definirana funkcija za prikaže najnovejšo vrednost identitete v tabeli pod trenutnim obsegom. Ta obseg je lahko modul, sprožilec, funkcija ali shranjena procedura. Podobna je funkciji @@IDENTITY(), le da ima ta funkcija le omejen obseg. Funkcija SCOPE_IDENTITY vrne NULL, če jo izvedemo pred operacijo vstavljanja, ki generira vrednost v istem obsegu.
Primer
Spodnja koda uporablja obe funkciji @@IDENTITY in SCOPE_IDENTITY() v isti seji. Ta primer bo najprej prikazal zadnjo vrednost identitete, nato pa bo v tabelo vstavil eno vrstico. Nato izvede obe funkciji identitete.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
Izvajanje kode bo prikazalo isto vrednost v trenutni seji in podoben obseg. Oglejte si spodnjo izhodno sliko:

Zdaj bomo na primeru videli, kako se obe funkciji razlikujeta. Najprej bomo ustvarili dve tabeli z imenom podatki_zaposlenega in oddelek z uporabo spodnje izjave:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Nato ustvarimo sprožilec INSERT v tabeli employee_data. Ta sprožilec se prikliče za vstavljanje vrstice v tabelo oddelka vsakič, ko vstavimo vrstico v tabelo Emploee_data.
Spodnja poizvedba ustvari sprožilec za vstavljanje privzete vrednosti 'IT' v tabeli oddelka pri vsaki poizvedbi za vstavljanje v tabeli podatkov o zaposlenih:
np.vsota
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Ko ustvarimo sprožilec, bomo v tabelo Emploee_data vstavili en zapis in si ogledali rezultate funkcij @@IDENTITY in SCOPE_IDENTITY().
INSERT INTO employee_data VALUES ('John Mathew');
Izvedba poizvedbe bo dodala eno vrstico v tabelo employee_data in ustvarila vrednost identitete v isti seji. Ko se poizvedba za vstavljanje izvede v tabeli Emploee_data, samodejno pokliče sprožilec za dodajanje ene vrstice v tabelo oddelka. Začetna vrednost identitete je 1 za podatke_zaposlenega in 100 za tabelo oddelka.
Na koncu izvedemo spodnje stavke, ki prikažejo izhod 100 za funkcijo SELECT @@IDENTITY in 1 za funkcijo SCOPE_IDENTITY, ker vrnejo vrednost identitete samo v istem obsegu.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Tukaj je rezultat:

Funkcija IDENT_CURRENT().
IDENT_CURRENT je sistemsko definirana funkcija za prikaže najnovejšo vrednost IDENTITY ustvarjen za dano tabelo pod katero koli povezavo. Ta funkcija ne upošteva obsega poizvedbe SQL, ki ustvari vrednost identitete. Ta funkcija zahteva ime tabele, za katero želimo pridobiti vrednost identitete.
Primer
Razumemo ga tako, da najprej odpremo dve okni za povezavo. V prvo okno bomo vstavili en zapis, ki generira vrednost identitete 15 v tabeli oseb. Nato lahko preverimo to vrednost identitete v drugem oknu povezave, kjer lahko vidimo isti rezultat. Tukaj je celotna koda:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
Izvajanje zgornjih kod v dveh različnih oknih bo prikazalo isto vrednost identitete.

Funkcija IDENTITY().
Funkcija IDENTITY() je sistemsko definirana funkcija uporablja se za vstavljanje stolpca identitete v novo tabelo . Ta funkcija se razlikuje od lastnosti IDENTITY, ki jo uporabljamo s stavkoma CREATE TABLE in ALTER TABLE. To funkcijo lahko uporabimo samo v stavku SELECT INTO, ki se uporablja pri prenosu podatkov iz ene tabele v drugo.
Naslednja sintaksa ponazarja uporabo te funkcije v strežniku SQL Server:
IDENTITY (data_type , seed , increment) AS column_name
Če ima izvorna tabela stolpec IDENTITY, ga tabela, oblikovana z ukazom SELECT INTO, privzeto podeduje. Na primer , smo predhodno ustvarili tabelo oseba s stolpcem identitete. Recimo, da ustvarimo novo tabelo, ki podeduje tabelo oseb z uporabo stavkov SELECT INTO s funkcijo IDENTITY(). V tem primeru bomo prejeli napako, ker izvorna tabela že ima stolpec identitete. Oglejte si spodnjo poizvedbo:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
Izvajanje zgornjega stavka bo vrnilo naslednje sporočilo o napaki:

Ustvarimo novo tabelo brez lastnosti identitete z uporabo spodnje izjave:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Nato kopirajte to tabelo s stavkom SELECT INTO, vključno s funkcijo IDENTITY, kot sledi:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Ko se izjava izvede, jo lahko preverimo z uporabo sp_help ukaz, ki prikaže lastnosti tabele.

Stolpec IDENTITETA si lahko ogledate v ZAKLJLJIV lastnosti v skladu z določenimi pogoji.
Če to funkcijo uporabimo s stavkom SELECT, bo SQL Server prikazal naslednje sporočilo o napaki:
Sporočilo 177, raven 15, stanje 1, vrstica 2 Funkcijo IDENTITY je mogoče uporabiti le, če ima stavek SELECT klavzulo INTO.
Ponovna uporaba vrednosti IDENTITY
Vrednosti identitete v tabeli strežnika SQL Server ne moremo ponovno uporabiti. Ko izbrišemo katero koli vrstico iz tabele stolpcev identitete, bo v stolpcu identitete ustvarjena vrzel. Poleg tega bo SQL Server ustvaril vrzel, ko vstavimo novo vrstico v stolpec identitete in stavek ni uspešen ali povrnjen. Vrzel označuje, da so vrednosti identitete izgubljene in jih ni mogoče znova generirati v stolpcu IDENTITY.
Razmislite o spodnjem primeru, da ga boste razumeli v praksi. Že imamo tabelo oseb, ki vsebuje naslednje podatke:

Nato bomo ustvarili še dve tabeli z imenom 'položaj' in ' položaj_osebe ' z uporabo naslednje izjave:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Nato poskušamo v tabelo oseb vstaviti nov zapis in jim dodeliti položaj tako, da v tabelo person_position dodamo novo vrstico. To bomo storili z uporabo izjave o transakciji, kot je spodaj:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
Zgornji skript kode transakcije uspešno izvede prvi stavek vstavljanja. Toda drugi stavek ni uspel, ker v tabeli pozicij ni bilo položaja z ID-jem deset. Zato je bila celotna transakcija razveljavljena.
Ker imamo največjo vrednost identitete v stolpcu PersonID 16, je prvi stavek vstavljanja porabil vrednost identitete 17, nato pa je bila transakcija povrnjena nazaj. Če torej v tabelo Oseba vstavimo naslednjo vrstico, bo naslednja vrednost identitete 18. Izvedite spodnji stavek:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Ko znova preverimo tabelo oseb, vidimo, da novo dodan zapis vsebuje vrednost identitete 18.

Dva stolpca IDENTITY v eni tabeli
Tehnično ni mogoče ustvariti dveh stolpcev z identiteto v eni tabeli. Če to storimo, SQL Server vrže napako. Oglejte si naslednjo poizvedbo:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Ko izvedemo to kodo, bomo videli naslednjo napako:

Vendar pa lahko ustvarimo dva stolpca identitete v eni tabeli z uporabo izračunanega stolpca. Naslednja poizvedba ustvari tabelo z izračunanim stolpcem, ki uporablja prvotni stolpec identitete in ga zmanjša za 1.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Nato bomo v to tabelo dodali nekaj podatkov s spodnjim ukazom:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Na koncu preverimo podatke tabele s stavkom SELECT. Vrne naslednje rezultate:

Na sliki lahko vidimo, kako stolpec SecondID deluje kot drugi stolpec identitete, ki se zmanjša za deset od začetne vrednosti 9990.
Napačne predstave o stolpcu IDENTITY strežnika SQL Server
Uporabnik DBA ima veliko napačnih predstav o stolpcih identitete strežnika SQL Server. Sledi seznam najpogostejših napačnih predstav o stolpcih identitete, ki bi jih lahko videli:
Stolpec IDENTITY je EDINSTVEN: V skladu z uradno dokumentacijo strežnika SQL lastnost identitete ne more zagotoviti, da je vrednost stolpca edinstvena. Za uveljavitev edinstvenosti stolpca moramo uporabiti PRIMARY KEY, omejitev UNIQUE ali indeks UNIQUE.
Stolpec IDENTITY generira zaporedne številke: Uradna dokumentacija jasno navaja, da se lahko dodeljene vrednosti v stolpcu identitete izgubijo ob okvari baze podatkov ali ponovnem zagonu strežnika. Med vstavljanjem lahko povzroči vrzeli v vrednosti identitete. Vrzel lahko nastane tudi, ko izbrišemo vrednost iz tabele ali ko se stavek vstavi vrne nazaj. Vrednosti, ki ustvarjajo vrzeli, ni mogoče nadalje uporabiti.
Stolpec IDENTITY ne more samodejno ustvariti obstoječih vrednosti: Stolpec identitete ne more samodejno generirati obstoječih vrednosti, dokler lastnost identitete ni znova vstavljena z uporabo ukaza DBCC CHECKIDENT. Omogoča nam prilagoditev semenske vrednosti (začetne vrednosti vrstice) lastnosti identitete. Po izvedbi tega ukaza SQL Server ne bo preveril, ali so na novo ustvarjene vrednosti že prisotne v tabeli ali ne.
Stolpec IDENTITY kot PRIMARNI KLJUČ zadostuje za identifikacijo vrstice: Če primarni ključ vsebuje stolpec identitete v tabeli brez drugih enoličnih omejitev, lahko stolpec shrani podvojene vrednosti in prepreči edinstvenost stolpca. Kot vemo, primarni ključ ne more shraniti podvojenih vrednosti, vendar lahko stolpec identitete shrani dvojnike; priporočljivo je, da primarnega ključa in lastnosti identitete ne uporabljate v istem stolpcu.
Uporaba napačnega orodja za vrnitev vrednosti identitete po vstavitvi: Prav tako je pogosta napačna predstava o nezavedanju razlik med funkcijami @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT in IDENTITY(), da se vrednost identitete vstavi neposredno iz stavka, ki smo ga pravkar izvedli.
Razlika med ZAPOREDJEM in IDENTITETO
Za generiranje samodejnih številk uporabljamo SEQUENCE in IDENTITY. Vendar ima nekaj razlik, glavna razlika pa je, da je identiteta odvisna od tabele, medtem ko zaporedje ni. Povzemimo njihove razlike v obliki tabele:
| IDENTITETA | ZAPOREDJE |
|---|---|
| Lastnost identitete se uporablja za določeno tabelo in je ni mogoče deliti z drugimi tabelami. | DBA definira objekt zaporedja, ki ga lahko deli več tabel, ker je neodvisen od tabele. |
| Ta lastnost samodejno ustvari vrednosti vsakič, ko se v tabeli izvede stavek vstavljanja. | Uporablja stavek NEXT VALUE FOR za ustvarjanje naslednje vrednosti za objekt zaporedja. |
| SQL Server ne ponastavi vrednosti stolpca lastnosti identitete na začetno vrednost. | SQL Server lahko ponastavi vrednost za objekt zaporedja. |
| Ne moremo nastaviti največje vrednosti za lastnost identitete. | Nastavimo lahko največjo vrednost za zaporedni objekt. |
| Predstavljen je v SQL Server 2000. | Predstavljen je v SQL Server 2012. |
| Ta lastnost ne more ustvariti vrednosti identitete v padajočem vrstnem redu. | Lahko ustvari vrednosti v padajočem vrstnem redu. |
Zaključek
Ta članek bo podal popoln pregled lastnosti IDENTITY v strežniku SQL Server. Tu smo se naučili, kako in kdaj se uporablja lastnost identitete, njene različne funkcije, napačne predstave in kako se razlikuje od zaporedja.