Kazalec v strežniku SQL je d atabase objekt, ki nam omogoča, da pridobimo vsako vrstico naenkrat in manipuliramo z njenimi podatki . Kazalec ni nič drugega kot kazalec na vrstico. Vedno se uporablja v povezavi s stavkom SELECT. Običajno gre za zbirko SQL logiko, ki eno za drugo kroži skozi vnaprej določeno število vrstic. Enostavna ilustracija kazalca je, ko imamo obsežno bazo podatkov o delavcih in želimo izračunati plačo vsakega delavca po odbitku davkov in dopustov.
SQL Server namen kazalca je posodobiti podatke vrstico za vrstico, jih spremeniti ali izvesti izračune, ki niso mogoči, ko pridobimo vse zapise hkrati . Uporaben je tudi za izvajanje skrbniških nalog, kot je varnostno kopiranje baze podatkov SQL Server v zaporednem vrstnem redu. Kazalci se večinoma uporabljajo v procesih razvoja, DBA in ETL.
Ta članek pojasnjuje vse o kazalcu SQL Server, kot je življenjski cikel kazalca, zakaj in kdaj se uporablja kazalec, kako implementirati kazalce, njegove omejitve in kako lahko zamenjamo kazalec.
Življenjski cikel kurzorja
Življenjski cikel kazalca lahko opišemo v pet različnih razdelkov kot sledi:
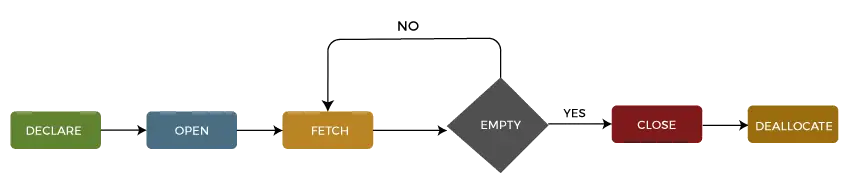
1: Razglasite kazalec
Prvi korak je deklaracija kazalca s spodnjim stavkom SQL:
linux ukazi ustvari mapo
DECLARE cursor_name CURSOR FOR select_statement;
Kazalec lahko deklariramo tako, da podamo njegovo ime s podatkovnim tipom CURSOR za ključno besedo DECLARE. Nato bomo napisali stavek SELECT, ki definira izhod za kazalec.
2: Odprite kazalec
To je drugi korak, v katerem odpremo kazalec za shranjevanje podatkov, pridobljenih iz nabora rezultatov. To lahko storimo z uporabo spodnje izjave SQL:
OPEN cursor_name;
3: Pridobi kazalec
To je tretji korak, v katerem je mogoče pridobiti vrstice eno za drugo ali v bloku, da izvedete manipulacijo s podatki, kot so operacije vstavljanja, posodabljanja in brisanja v trenutno aktivni vrstici v kazalcu. To lahko storimo z uporabo spodnje izjave SQL:
FETCH NEXT FROM cursor INTO variable_list;
Uporabimo lahko tudi Funkcija @@FETCHSTATUS v SQL Server, da dobite status zadnjega kazalca stavka FETCH, ki je bil izveden proti kazalcu. The PRINESI Stavek je bil uspešen, ko @@FETCHSTATUS daje ničelni rezultat. The MEDTEM lahko uporabite za pridobivanje vseh zapisov iz kazalca. Naslednja koda to bolj jasno razloži:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: Zapri kazalec
To je četrti korak, v katerem je treba kazalec zapreti, ko smo končali delo s kazalcem. To lahko storimo z uporabo spodnje izjave SQL:
CLOSE cursor_name;
5: Sprostite dodelitev kazalca
To je peti in zadnji korak, v katerem bomo izbrisali definicijo kazalca in sprostili vse sistemske vire, povezane s kazalcem. To lahko storimo z uporabo spodnje izjave SQL:
DEALLOCATE cursor_name;
Uporaba kazalca SQL Server
Vemo, da so sistemi za upravljanje relacijskih baz podatkov, vključno s strežnikom SQL, odlični pri obdelavi podatkov v nizu vrstic, imenovanih nizi rezultatov. Na primer , imamo mizo tabela_izdelkov ki vsebuje opise izdelkov. Če želimo posodobiti cena izdelka, nato spodnji ' NADGRADNJA' poizvedba bo posodobila vse zapise, ki se ujemajo s pogojem v ' KJE' klavzula:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
Včasih mora aplikacija obdelati vrstice na en sam način, tj. vrstico za vrstico in ne celotnega niza rezultatov hkrati. Ta postopek lahko izvedemo z uporabo kazalcev v SQL Serverju. Preden uporabimo kazalec, moramo vedeti, da so kazalci zelo slabi v delovanju, zato ga je treba vedno uporabljati le, če ni druge možnosti razen kazalca.
Kazalec uporablja isto tehniko, kot mi uporabljamo zanke, kot so FOREACH, FOR, WHILE, DO WHILE, za ponavljanje enega predmeta naenkrat v vseh programskih jezikih. Zato bi ga lahko izbrali, ker uporablja isto logiko kot proces zanke v programskem jeziku.
Vrste kazalcev v strežniku SQL
Spodaj so navedene različne vrste kazalcev v strežniku SQL:
- Statični kazalci
- Dinamični kazalci
- Kazalci samo za naprej
- Kazalci nabora tipk

Statični kazalci
Niz rezultatov, ki ga prikazuje statični kazalec, je vedno enak tistemu, ko je bil kazalec prvič odprt. Ker bo statični kazalec shranil rezultat v tempdb , vedno so le za branje . S statičnim kazalcem se lahko premikamo naprej in nazaj. V nasprotju z drugimi kazalci je počasnejši in porabi več pomnilnika. Posledično ga lahko uporabimo samo takrat, ko je drsenje potrebno, drugi kazalci pa niso primerni.
Ta kazalec prikazuje vrstice, ki so bile odstranjene iz zbirke podatkov, potem ko je bila odprta. Statični kazalec ne predstavlja nobenih operacij INSERT, UPDATE ali DELETE (razen če je kazalec zaprt in ponovno odprt).
Dinamični kazalci
Dinamični kazalci so v nasprotju s statičnimi kazalci, ki nam omogočajo izvajanje operacij posodabljanja, brisanja in vstavljanja podatkov, ko je kazalec odprt. je privzeto pomikanje . Zazna lahko vse spremembe vrstic, vrstnega reda in vrednosti v nizu rezultatov, ne glede na to, ali se spremembe zgodijo znotraj kazalca ali zunaj njega. Zunaj kazalca ne moremo videti posodobitev, dokler niso potrjene.
Kazalci samo za naprej
Je privzeti in najhitrejši tip kazalca med vsemi kazalci. Imenuje se kazalec samo za naprej, ker premika samo naprej skozi niz rezultatov . Ta kazalec ne podpira drsenja. Pridobi lahko le vrstice od začetka do konca nabora rezultatov. Omogoča nam izvajanje operacij vstavljanja, posodabljanja in brisanja. Tukaj je viden učinek operacij vstavljanja, posodabljanja in brisanja, ki jih izvede uporabnik in ki vplivajo na vrstice v nizu rezultatov, ko se vrstice pridobijo s kazalca. Ko je bila vrstica pridobljena, prek kazalca ne moremo videti sprememb vrstic.
Kazalci samo za naprej so trije razvrščeni v tri vrste:
- Forward_Only Keyset
- Forward_Only Static
- Hitro naprej

Kazalci, ki jih poganja nabor tipk
Ta funkcija kazalca leži med statičnim in dinamičnim kazalcem glede njegove sposobnosti zaznavanja sprememb. Ne more vedno zaznati sprememb v članstvu in vrstnem redu nabora rezultatov kot statični kazalec. Lahko zazna spremembe v vrednostih vrstic nabora rezultatov kot dinamični kazalec. Lahko samo premikanje od prve do zadnje in zadnje do prve vrstice . Vrstni red in članstvo sta določena vsakič, ko odprete ta kazalec.
Upravlja ga nabor enoličnih identifikatorjev, enakih ključem v naboru ključev. Nabor ključev je določen z vsemi vrsticami, ki so kvalificirale stavek SELECT, ko je bil kazalec prvič odprt. Prav tako lahko zazna kakršne koli spremembe vira podatkov, ki podpira operacije posodabljanja in brisanja. Privzeto se lahko premikate.
Izvedba primera
Implementirajmo primer kazalca v strežnik SQL. To lahko naredimo tako, da najprej ustvarimo tabelo z imenom ' stranka ' z uporabo spodnje izjave:
siva koda
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Nato bomo v tabelo vstavili vrednosti. Za dodajanje podatkov v tabelo lahko izvedemo spodnji stavek:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Podatke lahko preverimo tako, da izvedemo IZBERI izjava:
SELECT * FROM customer;
Po izvedbi poizvedbe lahko vidimo spodnji rezultat, kjer imamo osem vrstic v tabelo:

Zdaj bomo ustvarili kazalec za prikaz zapisov strank. Spodnji delčki kode pojasnjujejo vse korake deklaracije ali ustvarjanja kazalca tako, da vse skupaj sestavijo:
krepko besedilo v css
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Po izvedbi kazalca bomo dobili spodnji rezultat:

Omejitve SQL Server Cursor
Kazalec ima nekaj omejitev, tako da ga je treba vedno uporabljati le, če ni druge možnosti razen kazalca. Te omejitve so:
- Kazalec porablja omrežne vire tako, da zahteva povratno potovanje po omrežju vsakič, ko pridobi zapis.
- Kazalec je pomnilniški rezidenčni nabor kazalcev, kar pomeni, da zavzame nekaj pomnilnika, ki bi ga drugi procesi lahko uporabili na našem računalniku.
- Med obdelavo podatkov zaklene del tabele ali celotno tabelo.
- Delovanje in hitrost kazalca sta počasnejša, ker posodablja zapise tabele eno vrstico naenkrat.
- Kazalci so hitrejši od zank while, vendar imajo več dodatnih stroškov.
- Število vrstic in stolpcev v kazalcu je še en vidik, ki vpliva na hitrost kazalca. Nanaša se na to, koliko časa traja, da odprete kazalec in izvedete stavek fetch.
Kako se lahko izognemo kazalcem?
Glavna naloga kurzorjev je, da prečkajo tabelo vrstico za vrstico. Kazalcem se najlažje izognete spodaj:
Uporaba zanke SQL while
Uporabi kazalca se najlažje izognete z uporabo zanke while, ki omogoča vstavljanje niza rezultatov v začasno tabelo.
Uporabniško določene funkcije
Včasih se za izračun rezultantnega niza vrstic uporabljajo kazalci. To lahko dosežemo z uporabo uporabniško definirane funkcije, ki izpolnjuje zahteve.
Uporaba spojin
Join obdeluje samo tiste stolpce, ki izpolnjujejo podani pogoj, in tako zmanjša število vrstic kode, ki zagotavljajo hitrejšo zmogljivost kot kazalci, če je treba obdelati ogromne zapise.