En pomemben vidik Strojno učenje je vrednotenje modela. Za ovrednotenje svojega modela morate imeti nek mehanizem. Tu pridejo do izraza te meritve uspešnosti, ki nam dajo občutek, kako dober je model. Če ste seznanjeni z nekaterimi osnovami Strojno učenje potem ste gotovo naleteli na nekatere od teh meritev, kot so točnost, natančnost, priklic, auc-roc itd., ki se običajno uporabljajo za naloge klasifikacije. V tem članku bomo poglobljeno raziskali eno takšno metriko, to je krivuljo AUC-ROC.
Kazalo
- Kaj je krivulja AUC-ROC?
- Ključni izrazi, uporabljeni v krivulji AUC in ROC
- Razmerje med občutljivostjo, specifičnostjo, FPR in pragom.
- Kako deluje AUC-ROC?
- Kdaj naj uporabimo metriko vrednotenja AUC-ROC?
- Špekulacija o zmogljivosti modela
- Razumevanje krivulje AUC-ROC
- Izvedba z uporabo dveh različnih modelov
- Kako uporabiti ROC-AUC za model z več razredi?
- Pogosta vprašanja za krivuljo AUC ROC v strojnem učenju
Kaj je krivulja AUC-ROC?
Krivulja AUC-ROC ali krivulja Area Under Receiver Operating Characteristic je grafična predstavitev delovanja modela binarne klasifikacije pri različnih pragovih klasifikacije. Običajno se uporablja pri strojnem učenju za ocenjevanje sposobnosti modela za razlikovanje med dvema razredoma, običajno pozitivnim razredom (npr. prisotnost bolezni) in negativnim razredom (npr. odsotnost bolezni).
Najprej razumejmo pomen obeh izrazov ROC in AUC .
- ROC : Značilnosti delovanja sprejemnika
- AUC : Območje pod krivuljo
Krivulja delovanja sprejemnika (ROC).
ROC je kratica za Receiver Operating Characteristics, krivulja ROC pa je grafični prikaz učinkovitosti modela binarne klasifikacije. Prikazuje grafično stopnjo resničnih pozitivnih rezultatov (TPR) v primerjavi z lažno pozitivnimi stopnjami (FPR) pri različnih klasifikacijskih pragovih.
Območje pod krivuljo (AUC) krivulja:
AUC pomeni območje pod krivuljo, krivulja AUC pa predstavlja območje pod krivuljo ROC. Meri celotno zmogljivost modela binarne klasifikacije. Ker se TPR in FPR gibljeta med 0 in 1, bo torej območje vedno ležalo med 0 in 1, večja vrednost AUC pa pomeni boljšo zmogljivost modela. Naš glavni cilj je povečati to območje, da bi imeli najvišji TPR in najnižji FPR pri danem pragu. AUC meri verjetnost, da bo model naključno izbranemu pozitivnemu primerku dodelil višjo predvideno verjetnost v primerjavi z naključno izbranim negativnim primerkom.
Predstavlja verjetnost s katerim lahko naš model razlikuje med dvema razredoma, ki sta prisotna v našem cilju.
Merilo vrednotenja klasifikacije ROC-AUC
Ključni izrazi, uporabljeni v krivulji AUC in ROC
1. TPR in FPR
To je najpogostejša definicija, s katero bi se srečali, ko bi iskali v Googlu AUC-ROC. V bistvu je krivulja ROC graf, ki prikazuje učinkovitost klasifikacijskega modela pri vseh možnih pragovih (prag je določena vrednost, nad katero rečete, da točka pripada določenemu razredu). Krivulja je narisana med dvema parametroma
- TPR – Resnična pozitivna stopnja
- FPR – Stopnja lažno pozitivnih rezultatov
Preden razumemo TPR in FPR, si na hitro poglejmo matriko zmede .
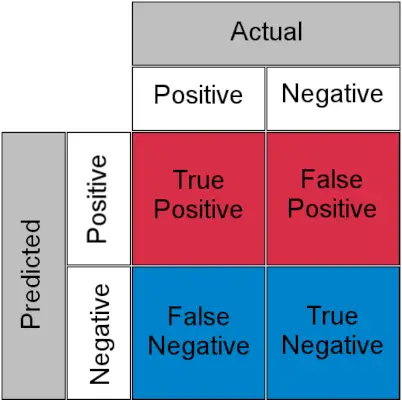
Matrika zmede za nalogo razvrščanja
- True Positive : Dejansko pozitivno in predvideno kot pozitivno
- Resnično negativno : Dejansko negativno in napovedano kot negativno
- Lažno pozitivno (napaka tipa I) : Dejansko negativno, vendar predvideno kot pozitivno
- Lažno negativno (napaka tipa II) : Dejansko pozitivno, vendar predvideno kot negativno
Preprosto povedano, lažno pozitivno lahko pokličete a lažni alarm in lažno negativno a zgrešiti . Zdaj pa poglejmo, kaj sta TPR in FPR.
2. Občutljivost/resnična pozitivna stopnja/priklic
V bistvu je TPR/Recall/Sensitivity razmerje pozitivnih primerov, ki so pravilno identificirani. Predstavlja zmožnost modela, da pravilno prepozna pozitivne primere, in se izračuna na naslednji način:

Občutljivost/priklic/TPR meri delež dejanskih pozitivnih primerov, ki jih model pravilno identificira kot pozitivne.
3. Lažno pozitivna stopnja
FPR je razmerje negativnih primerov, ki so nepravilno razvrščeni.

4. Specifičnost
Specifičnost meri delež dejanskih negativnih primerkov, ki jih model pravilno identificira kot negativne. Predstavlja sposobnost modela, da pravilno identificira negativne primere

In kot že rečeno, ROC ni nič drugega kot graf med TPR in FPR prek vseh možnih pragov, AUC pa je celotno območje pod to krivuljo ROC.
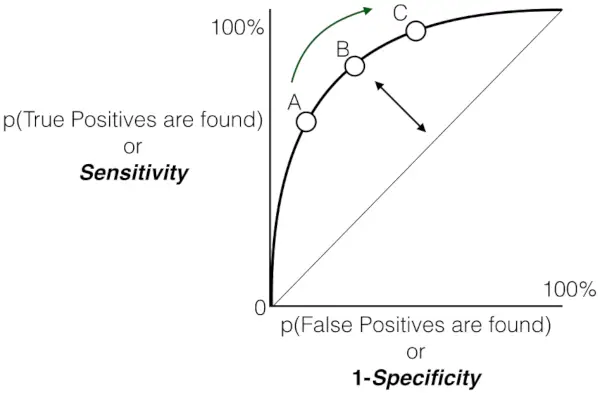
Graf občutljivosti v primerjavi s stopnjo lažnih pozitivnih rezultatov
Razmerje med občutljivostjo, specifičnostjo, FPR in pragom .
Občutljivost in specifičnost:
- Inverzno razmerje: občutljivost in specifičnost sta v obratnem razmerju. Ko se eden poveča, se drugi zmanjša. To odraža inherentno razmerje med resnično pozitivnimi in resnično negativnimi stopnjami.
- Nastavitev prek praga: S prilagoditvijo vrednosti praga lahko nadzorujemo ravnovesje med občutljivostjo in specifičnostjo. Nižji pragovi vodijo do višje občutljivosti (več resnično pozitivnih rezultatov) na račun specifičnosti (več lažnih pozitivnih rezultatov). Nasprotno pa zvišanje praga poveča specifičnost (manj lažnih pozitivnih rezultatov), vendar žrtvuje občutljivost (več lažnih negativnih rezultatov).
Prag in lažno pozitivna stopnja (FPR):
- FPR in povezava specifičnosti: False Positive Rate (FPR) je preprosto dopolnilo specifičnosti (FPR = 1 – specifičnost). To pomeni neposredno povezavo med njima: večja specifičnost pomeni nižji FPR in obratno.
- Spremembe FPR s TPR: Podobno sta, kot ste opazili, povezana tudi resnična pozitivna stopnja (TPR) in FPR. Povečanje TPR (več resničnih pozitivnih rezultatov) na splošno povzroči zvišanje FPR (več lažno pozitivnih rezultatov). Nasprotno, padec TPR (manj resničnih pozitivnih rezultatov) povzroči upad FPR (manj lažnih pozitivnih rezultatov)
Kako deluje AUC-ROC?
Ogledali smo si geometrijsko interpretacijo, vendar mislim, da še vedno ni dovolj za razvoj intuicije, kaj dejansko pomeni 0,75 AUC, zdaj pa si poglejmo AUC-ROC z verjetnostnega vidika. Najprej se pogovorimo o tem, kaj počne AUC, kasneje pa bomo na tem gradili naše razumevanje
AUC meri, kako dobro je model sposoben razlikovati med razredi.
AUC 0,75 bi dejansko pomenil, da recimo vzamemo dve podatkovni točki, ki pripadata ločenima razredoma, potem obstaja 75-odstotna možnost, da ju bo model lahko ločil ali pravilno razvrstil, tj. pozitivna točka ima večjo verjetnost napovedi kot negativna razred. (ob predpostavki večje verjetnosti napovedi pomeni, da bi točka idealno pripadala pozitivnemu razredu). Tukaj je majhen primer, da bodo stvari bolj jasne.
Kazalo | Razred | Verjetnost |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Tukaj imamo 6 točk, kjer P1, P2 in P5 pripadajo razredu 1, P3, P4 in P6 pa pripadajo razredu 0, in imamo ustrezne napovedane verjetnosti v stolpcu Verjetnost, kot smo rekli, če vzamemo dve točki, ki pripadata ločenima razredov, kakšna je verjetnost, da jih rang modela pravilno razporedi.
Vzeli bomo vse možne pare, tako da ena točka pripada razredu 1, druga pa razredu 0, skupaj bomo imeli 9 takih parov spodaj, vseh teh 9 možnih parov.
Par | je pravilen |
|---|---|
(P1,P3) | ja |
(P1,P4) | ja |
(P1,P6) | ja |
(P2,P3) | ja |
(P2,P4) | ja |
(P2,P6) | ja |
(P3,P5) | št |
(P4,P5) | št |
(P5,P6) | ja |
Tu stolpec Pravilno pove, ali je omenjeni par pravilno razvrščen glede na predvideno verjetnost, tj. točka razreda 1 ima večjo verjetnost kot točka razreda 0, v 7 od teh 9 možnih parov je razred 1 uvrščen višje od razreda 0 ali lahko rečemo, da obstaja 77-odstotna verjetnost, da bi jih model lahko pravilno razlikoval, če izberete par točk, ki pripadajo ločenim razredom. Zdaj pa mislim, da imate morda malo intuicije za to številko AUC, samo da razčistimo morebitne nadaljnje dvome, jo potrdimo z uporabo izvajanja Scikit se uči AUC-ROC.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Izhod:
AUC for our sample data is 0.778>
Kdaj naj uporabimo metriko vrednotenja AUC-ROC?
Na nekaterih področjih uporaba ROC-AUC morda ni idealna. V primerih, ko je nabor podatkov zelo neuravnotežen, krivulja ROC lahko daje preveč optimistično oceno delovanja modela . Ta pristranskost optimizma nastane, ker lahko stopnja lažnih pozitivnih rezultatov (FPR) krivulje ROC postane zelo majhna, ko je število dejanskih negativnih rezultatov veliko.
Če pogledamo formulo FPR,

opazujemo ,
- Negativni razred je v večini, v imenovalcu FPR prevladujejo True Negatives, zaradi česar postane FPR manj občutljiv na spremembe napovedi, povezane z manjšinskim razredom (pozitivni razred).
- Krivulje ROC so lahko primerne, če so stroški lažno pozitivnih in lažno negativnih rezultatov uravnoteženi in nabor podatkov ni močno neuravnotežen.
V tem primeru Precision-Recall krivulje ki zagotavljajo alternativno metriko vrednotenja, ki je bolj primerna za neuravnotežene nize podatkov, s poudarkom na uspešnosti klasifikatorja glede na pozitivni (manjšinski) razred.
Špekulacija o zmogljivosti modela
- Visoka AUC (blizu 1) kaže na odlično razlikovalno moč. To pomeni, da je model učinkovit pri razlikovanju med obema razredoma, njegove napovedi pa so zanesljive.
- Nizka AUC (blizu 0) kaže na slabo delovanje. V tem primeru se model trudi razlikovati med pozitivnimi in negativnimi razredi, zato njegove napovedi morda niso vredne zaupanja.
- AUC okoli 0,5 pomeni, da model v bistvu naključno ugiba. Ne kaže zmožnosti ločevanja razredov, kar kaže, da se model ne uči nobenih pomembnih vzorcev iz podatkov.
Razumevanje krivulje AUC-ROC
V krivulji ROC os x običajno predstavlja stopnjo lažnih pozitivnih rezultatov (FPR), os y pa stopnjo pravih pozitivnih rezultatov (TPR), znano tudi kot občutljivost ali priklic. Torej višja vrednost na osi x (proti desni) na krivulji ROC res pomeni višjo stopnjo lažno pozitivnih rezultatov, višja vrednost na osi y (proti vrhu) pa kaže višjo stopnjo resnično pozitivnih rezultatov. Krivulja ROC je grafična predstavitev kompromisa med resnično pozitivno stopnjo in lažno pozitivno stopnjo pri različnih pragovih. Prikazuje učinkovitost klasifikacijskega modela pri različnih klasifikacijskih pragovih. AUC (območje pod krivuljo) je povzetek merila učinkovitosti krivulje ROC. Izbira praga je odvisna od posebnih zahtev težave, ki jo poskušate rešiti, in kompromisa med lažno pozitivnimi in lažno negativnimi rezultati, ki je sprejemljivo v vašem kontekstu.
- Če želite dati prednost zmanjševanju lažno pozitivnih rezultatov (zmanjšanje možnosti, da bi nekaj označili kot pozitivno, če ni), lahko izberete prag, ki ima za posledico nižjo stopnjo lažnih pozitivnih rezultatov.
- Če želite dati prednost povečevanju resničnih pozitivnih rezultatov (zajeti čim več dejanskih pozitivnih rezultatov), lahko izberete prag, ki povzroči višjo stopnjo resničnih pozitivnih rezultatov.
Oglejmo si primer za ponazoritev, kako se krivulje ROC ustvarijo za različne pragovi in kako določen prag ustreza matriki zmede. Recimo, da imamo a problem binarne klasifikacije z modelom, ki predvideva, ali je e-poštno sporočilo vsiljena pošta (pozitivno) ali ni vsiljena pošta (negativno).
Poglejmo hipotetične podatke,
Resnične oznake: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Predvidene verjetnosti: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
1. primer: prag = 0,5
Resnične oznake | Predvidene verjetnosti | Predvidene oznake |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrika zmede, ki temelji na zgornjih napovedih
| Napoved = 0 | Napoved = 1 |
|---|---|---|
Dejansko = 0 | TP=4 | FN=1 |
Dejansko = 1 | FP=0 | TN=5 |
V skladu s tem
- Prava pozitivna stopnja (TPR) :
Delež dejanskih pozitivnih rezultatov, ki jih je klasifikator pravilno identificiral, je

- False Positive Rate (FPR) :
Delež dejanskih negativov, ki so napačno razvrščeni kot pozitivni



Torej, pri pragu 0,5:
- Prava pozitivna stopnja (občutljivost): 0,8
- Stopnja lažno pozitivnih rezultatov: 0
Razlaga je, da model pri tem pragu pravilno identificira 80 % dejanskih pozitivnih rezultatov (TPR), vendar nepravilno razvrsti 0 % dejanskih negativnih rezultatov kot pozitivnih (FPR).
V skladu s tem za različne pragove bomo dobili
2. primer: prag = 0,7
Resnične oznake | Predvidene verjetnosti | Predvidene oznake |
|---|---|---|
| 1 kako razkriti aplikacijo v androidu | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Matrika zmede, ki temelji na zgornjih napovedih
| Napoved = 0 | Napoved = 1 |
|---|---|---|
Dejansko = 0 | TP=5 | FN=0 |
Dejansko = 1 | FP=2 | TN=3 |
V skladu s tem
- Prava pozitivna stopnja (TPR) :
Delež dejanskih pozitivnih rezultatov, ki jih je klasifikator pravilno identificiral, je

- False Positive Rate (FPR) :
Delež dejanskih negativov, ki so napačno razvrščeni kot pozitivni



3. primer: Prag = 0,4
Resnične oznake | Predvidene verjetnosti | Predvidene oznake |
|---|---|---|
| 1 | 0,8 sort arraylist | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrika zmede, ki temelji na zgornjih napovedih
| Napoved = 0 | Napoved = 1 |
|---|---|---|
Dejansko = 0 | TP=4 | FN=1 |
Dejansko = 1 | FP=0 | TN=5 |
V skladu s tem
- Prava pozitivna stopnja (TPR) :
Delež dejanskih pozitivnih rezultatov, ki jih je klasifikator pravilno identificiral, je
- False Positive Rate (FPR) :
Delež dejanskih negativov, ki so napačno razvrščeni kot pozitivni
Primer 4: Prag = 0,2
Resnične oznake | Predvidene verjetnosti | Predvidene oznake |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matrika zmede, ki temelji na zgornjih napovedih
| Napoved = 0 | Napoved = 1 |
|---|---|---|
Dejansko = 0 | TP=2 | FN=3 |
Dejansko = 1 | FP=0 | TN=5 |
V skladu s tem
- Prava pozitivna stopnja (TPR) :
Delež dejanskih pozitivnih rezultatov, ki jih je klasifikator pravilno identificiral, je

- False Positive Rate (FPR) :
Delež dejanskih negativov, ki so napačno razvrščeni kot pozitivni

Primer 5: Prag = 0,85
Resnične oznake | Predvidene verjetnosti | Predvidene oznake |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Matrika zmede, ki temelji na zgornjih napovedih
| Napoved = 0 | Napoved = 1 |
|---|---|---|
Dejansko = 0 | TP=5 | FN=0 |
Dejansko = 1 | FP=4 | TN=1 |
V skladu s tem
- Prava pozitivna stopnja (TPR) :
Delež dejanskih pozitivnih rezultatov, ki jih je klasifikator pravilno identificiral, je
- False Positive Rate (FPR) :
Delež dejanskih negativov, ki so napačno razvrščeni kot pozitivni


Na podlagi zgornjega rezultata bomo izrisali krivuljo ROC
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Izhod:
Iz grafa je razvidno, da:
- Siva črtkana črta predstavlja najslabši možni scenarij, kjer so napovedi modela, tj. TPR in FPR, enake. Ta diagonalna črta velja za najslabši možni scenarij, ki kaže enako verjetnost lažno pozitivnih in lažno negativnih rezultatov.
- Ko točke odstopajo od naključne črte ugibanja proti zgornjemu levemu kotu, se zmogljivost modela izboljša.
- Območje pod krivuljo (AUC) je kvantitativno merilo diskriminatorne sposobnosti modela. Višja vrednost AUC, bližje 1,0, kaže na boljše delovanje. Najboljša možna vrednost AUC je 1,0, kar ustreza modelu, ki doseže 100-odstotno občutljivost in 100-odstotno specifičnost.
V celoti služi krivulja delovanja sprejemnika (ROC) kot grafični prikaz kompromisa med resnično pozitivno stopnjo (občutljivost) in lažno pozitivno stopnjo modela binarne klasifikacije pri različnih pragovih odločanja. Ko se krivulja graciozno dviga proti zgornjemu levemu kotu, to pomeni hvalevredno sposobnost modela, da razlikuje med pozitivnimi in negativnimi primeri v razponu pragov zaupanja. Ta pot navzgor kaže na izboljšano zmogljivost z doseženo višjo občutljivostjo ob zmanjšanju lažnih pozitivnih rezultatov. Označeni pragovi, označeni kot A, B, C, D in E, ponujajo dragocene vpoglede v dinamično obnašanje modela pri različnih stopnjah zaupanja.
Izvedba z uporabo dveh različnih modelov
Namestitev knjižnic
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Da bi usposobili Naključni gozd in Logistična regresija modelov in za predstavitev njihovih krivulj ROC z rezultati AUC algoritem ustvari umetne podatke binarne klasifikacije.
Generiranje podatkov in razdelitev podatkov
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Z uporabo razmerja delitve 80-20 algoritem ustvari umetne podatke binarne klasifikacije z 20 značilnostmi, jih razdeli na nize za usposabljanje in testiranje ter dodeli naključno seme, da zagotovi ponovljivost.
Usposabljanje različnih modelov
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Z uporabo fiksnega naključnega semena za zagotovitev ponovljivosti metoda inicializira in uri logistični regresijski model na učnem nizu. Na podoben način uporablja podatke o usposabljanju in isto naključno seme za inicializacijo in usposabljanje modela Random Forest s 100 drevesi.
Napovedi
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Z uporabo testnih podatkov in usposobljenega Logistična regresija model, koda napove verjetnost pozitivnega razreda. Na podoben način z uporabo testnih podatkov uporablja usposobljeni model Random Forest za izdelavo predvidenih verjetnosti za pozitivni razred.
Ustvarjanje podatkovnega okvira
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Z uporabo testnih podatkov koda ustvari DataFrame, imenovan test_df, s stolpci z oznakami True, Logistic in RandomForest ter doda prave oznake in predvidene verjetnosti iz modelov Random Forest in Logistic Regression.
Narišite krivuljo ROC za modele
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Izhod:

Koda ustvari risbo s figurami 8 x 6 palcev. Izračuna krivuljo AUC in ROC za vsak model (naključni gozd in logistična regresija), nato pa nariše krivuljo ROC. The ROC krivulja za naključno ugibanje je predstavljen tudi z rdečo črtkano črto, oznake, naslov in legenda pa so nastavljeni za vizualizacijo.
Kako uporabiti ROC-AUC za model z več razredi?
Za nastavitev več razredov lahko preprosto uporabimo metodologijo eden proti vsem in imeli boste eno krivuljo ROC za vsak razred. Recimo, da imate štiri razrede A, B, C in D, potem bi obstajale ROC krivulje in ustrezne vrednosti AUC za vse štiri razrede, tj. ko bi bil A en razred, B, C in D skupaj pa drugi razred , podobno je B en razred, A, C in D pa skupaj kot drugi razredi itd.
Splošni koraki za uporabo AUC-ROC v kontekstu večrazrednega klasifikacijskega modela so:
Metodologija Eden proti vsem:
- Za vsak razred v vašem večrazrednem problemu ga obravnavajte kot pozitivni razred, medtem ko združite vse druge razrede v negativni razred.
- Usposobite binarni klasifikator za vsak razred v primerjavi z ostalimi razredi.
Izračunajte AUC-ROC za vsak razred:
- Tukaj narišemo krivuljo ROC za dani razred v primerjavi z ostalimi.
- Na isti graf narišite krivulje ROC za vsak razred. Vsaka krivulja predstavlja diskriminacijsko zmogljivost modela za določen razred.
- Preglejte rezultate AUC za vsak razred. Višji rezultat AUC pomeni boljšo diskriminacijo za ta določen razred.
Implementacija AUC-ROC v večrazredni klasifikaciji
Uvažanje knjižnic
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Program ustvari umetne večrazredne podatke, jih razdeli na nize za usposabljanje in testiranje, nato pa uporabi One-vs-Restclassifier tehnika za usposabljanje klasifikatorjev za naključni gozd in logistično regresijo. Nazadnje izriše večrazredne ROC krivulje obeh modelov, da pokaže, kako dobro razlikujeta med različnimi razredi.
Ustvarjanje podatkov in razdelitev
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Trije razredi in dvajset funkcij sestavljajo sintetične večrazredne podatke, ki jih ustvari koda. Po binarizaciji oznak so podatki razdeljeni na nize za usposabljanje in testiranje v razmerju 80-20.
Modeli usposabljanja
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Program usposablja dva večrazredna modela: model Random Forest s 100 ocenjevalci in model logistične regresije z Pristop ena proti ostalim . Z učnim nizom podatkov sta oba modela opremljena.
Risanje krivulje AUC-ROC
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Izhod:

Krivulje ROC in AUC modelov naključnega gozda in logistične regresije se izračunajo s kodo za vsak razred. Nato se narišejo večrazredne krivulje ROC, ki prikazujejo diskriminacijsko učinkovitost vsakega razreda in prikazujejo črto, ki predstavlja naključno ugibanje. Dobljeni prikaz ponuja grafično oceno učinkovitosti klasifikacije modelov.
Zaključek
Pri strojnem učenju se uspešnost binarnih klasifikacijskih modelov ocenjuje z uporabo ključne metrike, imenovane območje pod delovno karakteristiko sprejemnika (AUC-ROC). Na različnih pragovih odločanja prikazuje, kako se izmenjujeta občutljivost in specifičnost. Večjo diskriminacijo med pozitivnimi in negativnimi primerki običajno kaže model z višjo oceno AUC. Medtem ko 0,5 pomeni možnost, 1 predstavlja brezhibno delovanje. Optimizacija in izbira modela sta v pomoč z uporabnimi informacijami, ki jih ponuja krivulja AUC-ROC o zmožnosti modela za razlikovanje med razredi. Pri delu z neuravnoteženimi nabori podatkov ali aplikacijami, kjer imajo lažno pozitivni in lažno negativni rezultati različne stroške, je še posebej uporaben kot celovit ukrep.
Pogosta vprašanja za krivuljo AUC ROC v strojnem učenju
1. Kaj je krivulja AUC-ROC?
Za različne klasifikacijske pragove je kompromis med resnično pozitivno stopnjo (občutljivost) in lažno pozitivno stopnjo (specifičnost) grafično predstavljen s krivuljo AUC-ROC.
2. Kako izgleda popolna krivulja AUC-ROC?
Območje 1 na idealni krivulji AUC-ROC bi pomenilo, da model dosega optimalno občutljivost in specifičnost pri vseh pragovih.
3. Kaj pomeni vrednost AUC 0,5?
AUC 0,5 pomeni, da je zmogljivost modela primerljiva z zmogljivostjo naključnega slučaja. Nakazuje pomanjkanje sposobnosti razlikovanja.
4. Ali se lahko AUC-ROC uporablja za večrazredno razvrščanje?
AUC-ROC se pogosto uporablja za vprašanja, ki vključujejo binarno klasifikacijo. Različice, kot je makropovprečje ali mikropovprečje AUC, se lahko upoštevajo pri klasifikaciji v več razredov.
5. Kako je krivulja AUC-ROC uporabna pri vrednotenju modela?
Sposobnost modela, da razlikuje med razredi, je izčrpno povzeta s krivuljo AUC-ROC. Pri delu z neuravnoteženimi nabori podatkov je še posebej koristen.