Od izuma računalnikov ljudje uporabljajo izraz ' podatki ' za sklicevanje na računalniške informacije, bodisi posredovane ali shranjene. Vendar pa obstajajo podatki, ki obstajajo tudi v vrstah naročil. Podatki so lahko številke ali besedila, napisana na kos papirja, v obliki bitov in bajtov, shranjenih v pomnilniku elektronskih naprav, ali dejstva, shranjena v človekovem umu. Ko se je svet začel modernizirati, so ti podatki postali pomemben vidik vsakodnevnega življenja vseh, različne izvedbe pa so jim omogočile drugačno shranjevanje.
podatki je zbirka dejstev in številk ali niz vrednosti ali vrednosti določenega formata, ki se nanaša na en sam niz vrednosti postavk. Podatkovne postavke so nato razvrščene v podpostavke, ki so skupine postavk, ki niso znane kot preprosta primarna oblika postavke.
Oglejmo si primer, kjer lahko ime zaposlenega razdelimo na tri podpostavke: prvo, srednje in zadnje. Vendar se bo ID, dodeljen zaposlenemu, na splošno obravnaval kot en element.
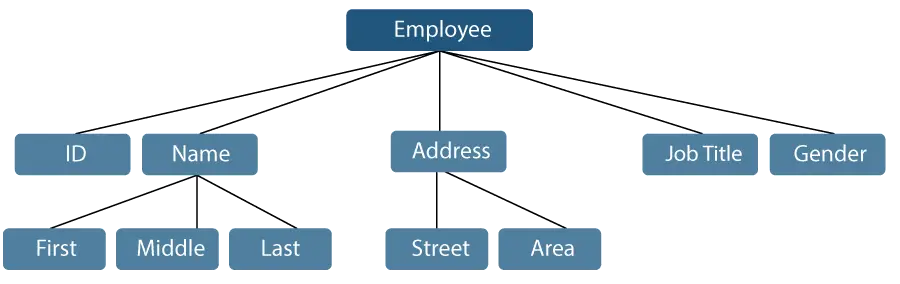
Slika 1: Predstavitev podatkovnih postavk
V zgoraj omenjenem primeru so postavke, kot so ID, starost, spol, ime, sredina, zadnja, ulica, kraj itd., osnovne podatkovne postavke. V nasprotju s tem sta ime in naslov podatkovni postavki skupine.
Kaj je struktura podatkov?
Struktura podatkov je veja računalništva. Preučevanje strukture podatkov nam omogoča razumevanje organizacije podatkov in upravljanja pretoka podatkov, da bi povečali učinkovitost katerega koli procesa ali programa. Struktura podatkov je poseben način shranjevanja in organiziranja podatkov v pomnilniku računalnika, tako da je te podatke mogoče preprosto pridobiti in učinkovito uporabiti v prihodnosti, ko bo to potrebno. S podatki je mogoče upravljati na različne načine, na primer logični ali matematični model za določeno organizacijo podatkov je znan kot podatkovna struktura.
Obseg določenega podatkovnega modela je odvisen od dveh dejavnikov:
- Najprej mora biti dovolj naložen v strukturo, da odraža določeno korelacijo podatkov z objektom iz resničnega sveta.
- Drugič, oblikovanje mora biti tako preprosto, da se lahko prilagodi za učinkovito obdelavo podatkov, kadar koli je to potrebno.
Nekaj primerov podatkovnih struktur so polja, povezani seznami, skladi, čakalne vrste, drevesa itd. Podatkovne strukture se široko uporabljajo v skoraj vseh vidikih računalništva, npr. pri oblikovanju prevajalnika, operacijskih sistemih, grafiki, umetni inteligenci in še veliko več.
Podatkovne strukture so glavni del številnih algoritmov računalništva, saj programerjem omogočajo učinkovito upravljanje podatkov. Ima ključno vlogo pri izboljšanju delovanja programa ali programske opreme, saj je glavni cilj programske opreme čim hitrejše shranjevanje in pridobivanje podatkov uporabnika.
naključno c
Osnovne terminologije, povezane s podatkovnimi strukturami
Podatkovne strukture so gradniki katere koli programske opreme ali programa. Izbira primerne strukture podatkov za program je za programerja izjemno zahtevna naloga.
Sledi nekaj temeljnih terminologij, ki se uporabljajo, ko gre za podatkovne strukture:
| Lastnosti | ID | Ime | Spol | Naziv delovnega mesta |
|---|---|---|---|---|
| Vrednote | 1234 | Stacey M. Hill | ženska | Razvijalec programske opreme |
Entitete s podobnimi atributi tvorijo an Nabor entitet . Vsak atribut nabora entitet ima obseg vrednosti, nabor vseh možnih vrednosti, ki jih je mogoče dodeliti določenemu atributu.
Izraz 'informacija' se včasih uporablja za podatke z danimi atributi pomembnih ali obdelanih podatkov.
Razumevanje potrebe po podatkovnih strukturah
Ker aplikacije postajajo vse bolj zapletene in se količina podatkov vsak dan povečuje, lahko pride do težav pri iskanju podatkov, hitrosti obdelave, obravnavanju več zahtevkov in še mnogo več. Podatkovne strukture podpirajo različne metode za učinkovito organiziranje, upravljanje in shranjevanje podatkov. S pomočjo podatkovnih struktur lahko enostavno prečkamo podatkovne postavke. Podatkovne strukture zagotavljajo učinkovitost, možnost ponovne uporabe in abstrakcijo.
Zakaj bi se morali naučiti podatkovnih struktur?
- Podatkovne strukture in algoritmi sta dva od ključnih vidikov računalništva.
- Podatkovne strukture nam omogočajo organiziranje in shranjevanje podatkov, medtem ko nam algoritmi omogočajo smiselno obdelavo teh podatkov.
- Učenje podatkovnih struktur in algoritmov nam bo pomagalo postati boljši programerji.
- Lahko bomo napisali kodo, ki bo bolj učinkovita in zanesljiva.
- Prav tako bomo hitreje in učinkoviteje reševali težave.
Razumevanje ciljev podatkovnih struktur
Podatkovne strukture izpolnjujejo dva komplementarna cilja:
Razumevanje nekaterih ključnih značilnosti podatkovnih struktur
Nekatere izmed pomembnih lastnosti podatkovnih struktur so:
Klasifikacija podatkovnih struktur
Podatkovna struktura zagotavlja strukturiran niz spremenljivk, ki so med seboj povezane na različne načine. Tvori osnovo programskega orodja, ki označuje razmerje med podatkovnimi elementi in programerjem omogoča učinkovito obdelavo podatkov.
pretvorba niza v int java
Podatkovne strukture lahko razvrstimo v dve kategoriji:
- Primitivna struktura podatkov
- Neprimitivna struktura podatkov
Naslednja slika prikazuje različne klasifikacije podatkovnih struktur.

Slika 2: Klasifikacije podatkovnih struktur
Primitivne podatkovne strukture
- S temi podatkovnimi strukturami je mogoče manipulirati ali upravljati neposredno z navodili na ravni stroja.
- Osnovne vrste podatkov, kot je Celo število, plavajoče število, znak , in Boolean spadajo pod primitivne podatkovne strukture.
- Ti tipi podatkov se tudi imenujejo Enostavni tipi podatkov , saj vsebujejo znake, ki jih ni mogoče nadalje deliti
Neprimitivne podatkovne strukture
- S temi podatkovnimi strukturami ni mogoče manipulirati ali jih upravljati neposredno z navodili na ravni stroja.
- Te podatkovne strukture se osredotočajo na oblikovanje niza podatkovnih elementov, ki je bodisi homogena (isti podatkovni tip) oz heterogena (različni tipi podatkov).
- Na podlagi strukture in razporeditve podatkov lahko te podatkovne strukture razdelimo v dve podkategoriji -
- Linearne podatkovne strukture
- Nelinearne podatkovne strukture
Linearne podatkovne strukture
Podatkovna struktura, ki ohranja linearno povezavo med svojimi podatkovnimi elementi, je znana kot linearna podatkovna struktura. Razporeditev podatkov je linearna, kjer je vsak element sestavljen iz naslednikov in predhodnikov, razen prvega in zadnjega podatkovnega elementa. Vendar to ni nujno res v primeru spomina, saj razporeditev morda ni zaporedna.
Na podlagi dodelitve pomnilnika so linearne podatkovne strukture nadalje razvrščene v dve vrsti:
The Array je najboljši primer statične podatkovne strukture, saj imajo fiksno velikost, njene podatke pa je mogoče pozneje spremeniti.
Povezani seznami, skladi , in Repi so pogosti primeri dinamičnih podatkovnih struktur
Vrste linearnih podatkovnih struktur
Sledi seznam linearnih podatkovnih struktur, ki jih običajno uporabljamo:
1. Nizi
An Array je podatkovna struktura, ki se uporablja za zbiranje več podatkovnih elementov iste vrste podatkov v eno spremenljivko. Namesto shranjevanja več vrednosti istih tipov podatkov v ločenih imenih spremenljivk, bi jih lahko shranili vse skupaj v eno spremenljivko. Ta izjava ne pomeni, da bomo morali združiti vse vrednosti iste podatkovne vrste v katerem koli programu v eno matriko te podatkovne vrste. Toda pogosto bodo nekatere posebne spremenljivke istih tipov podatkov med seboj povezane na način, primeren za matriko.
Matrika je seznam elementov, kjer ima vsak element edinstveno mesto na seznamu. Podatkovni elementi matrike imajo isto ime spremenljivke; vendar ima vsak drugačno indeksno številko, ki se imenuje indeks. Do katerega koli podatkovnega elementa s seznama lahko dostopamo s pomočjo njegove lokacije na seznamu. Tako je ključna značilnost matrik, ki jih je treba razumeti, ta, da so podatki shranjeni na sosednjih pomnilniških lokacijah, kar uporabnikom omogoča, da se premikajo po podatkovnih elementih matrike z uporabo njihovih ustreznih indeksov.

Slika 3. Niz
Nize lahko razvrstimo v različne vrste:
Nekaj aplikacij Array:
- Shranimo lahko seznam podatkovnih elementov, ki pripadajo istemu podatkovnemu tipu.
- Array deluje kot pomožna shramba za druge podatkovne strukture.
- Matrika pomaga tudi pri shranjevanju podatkovnih elementov binarnega drevesa s fiksnim številom.
- Array deluje tudi kot shramba matrik.
2. Povezani seznami
odstranitev zadnje objave git
A Povezan seznam je še en primer linearne podatkovne strukture, ki se uporablja za dinamično shranjevanje zbirke podatkovnih elementov. Podatkovne elemente v tej podatkovni strukturi predstavljajo vozlišča, povezana s povezavami ali kazalci. Vsako vozlišče vsebuje dve polji, informacijsko polje je sestavljeno iz dejanskih podatkov, polje kazalca pa je sestavljeno iz naslovov naslednjih vozlišč na seznamu. Kazalec zadnjega vozlišča povezanega seznama je sestavljen iz ničelnega kazalca, saj ne kaže na nič. Za razliko od nizov lahko uporabnik dinamično prilagodi velikost povezanega seznama glede na zahteve.

Slika 4. Povezan seznam
Povezane sezname je mogoče razvrstiti v različne vrste:
Nekatere uporabe povezanih seznamov:
- Povezani seznami nam pomagajo implementirati sklade, čakalne vrste, binarna drevesa in grafe vnaprej določene velikosti.
- Prav tako lahko implementiramo funkcijo operacijskega sistema za dinamično upravljanje pomnilnika.
- Povezani seznami omogočajo tudi polinomsko implementacijo za matematične operacije.
- Krožni povezani seznam lahko uporabimo za implementacijo operacijskih sistemov ali aplikacijskih funkcij, ki krožno izvajajo naloge.
- Krožni povezani seznam je koristen tudi pri diaprojekciji, kjer se mora uporabnik po predstavitvi zadnjega diapozitiva vrniti na prvi diapozitiv.
- Dvojno povezani seznam se uporablja za izvajanje gumbov naprej in nazaj v brskalniku za premikanje naprej in nazaj na odprtih straneh spletnega mesta.
3. Zloženke
A Stack je linearna podatkovna struktura, ki sledi LIFO Načelo (Last In, First Out), ki omogoča operacije, kot sta vstavljanje in brisanje z enega konca sklada, tj. Sklade je mogoče implementirati s pomočjo sosednjega pomnilnika, matrike, in nesosednjega pomnilnika, povezanega seznama. Primeri skladov iz resničnega življenja so kupi knjig, komplet kart, kupi denarja in še veliko več.

Slika 5. Primer sklada iz resničnega življenja
Zgornja slika predstavlja primer sklada iz resničnega življenja, kjer se operacije izvajajo samo z enega konca, na primer vstavljanje in odstranjevanje novih knjig z vrha sklada. To pomeni, da je vstavljanje in brisanje v sklad mogoče izvesti samo z vrha sklada. V danem trenutku lahko dostopamo le do vrhov sklada.
Primarne operacije v skladu so naslednje:

Slika 6. Stack
Nekaj aplikacij skladov:
- Sklad se uporablja kot začasna pomnilniška struktura za rekurzivne operacije.
- Sklad se uporablja tudi kot pomožna pomnilniška struktura za klice funkcij, ugnezdene operacije in odložene/preložene funkcije.
- Funkcijske klice lahko upravljamo z uporabo skladov.
- Skladi se uporabljajo tudi za vrednotenje aritmetičnih izrazov v različnih programskih jezikih.
- Skladi so prav tako v pomoč pri pretvorbi infiksnih izrazov v postfiksne izraze.
- Skladi nam omogočajo, da preverimo sintakso izraza v programskem okolju.
- Oklepaje lahko povežemo z uporabo skladov.
- Skladi se lahko uporabljajo za obračanje niza.
- Skladi so v pomoč pri reševanju težav, ki temeljijo na sledenju nazaj.
- Stacks lahko uporabimo pri iskanju najprej v globino v grafu in prečkanju drevesa.
- Skladi se uporabljajo tudi v funkcijah operacijskega sistema.
- Skladi se uporabljajo tudi v funkcijah UNDO in REDO pri urejanju.
4. Repi
A Čakalna vrsta je linearna podatkovna struktura, podobna skladu, z nekaterimi omejitvami pri vstavljanju in brisanju elementov. Vstavljanje elementa v čakalno vrsto se izvede na enem koncu, odstranitev pa na drugem ali nasprotnem koncu. Tako lahko sklepamo, da struktura podatkov Queue sledi načelu FIFO (First In, First Out) za manipulacijo podatkovnih elementov. Implementacijo čakalnih vrst je mogoče izvesti z uporabo nizov, povezanih seznamov ali skladov. Nekateri primeri čakalnih vrst iz resničnega življenja so vrsta pri blagajni, tekoče stopnice, avtopralnica in še veliko več.

Slika 7. Primer čakalne vrste iz resničnega življenja
Zgornja slika je resnična ilustracija števca vstopnic za kino, ki nam lahko pomaga razumeti čakalno vrsto, kjer je stranka, ki pride prva, vedno prva postrežena. Stranka, ki pride zadnja, bo nedvomno postrežena zadnja. Oba konca čakalne vrste sta odprta in lahko izvajata različne operacije. Drug primer je linija dvorišča s hrano, kjer se stranka vstavi z zadnjega dela, medtem ko se stranka odstrani na sprednjem koncu, potem ko je zagotovila storitev, ki jo je zahtevala.
Sledijo glavne operacije čakalne vrste:

Slika 8. Čakalna vrsta
Nekaj aplikacij čakalnih vrst:
- Čakalne vrste se običajno uporabljajo v operaciji iskanja po širini v Graphs.
- Čakalne vrste se uporabljajo tudi v operacijah razporejevalnika opravil v operacijskih sistemih, kot je čakalna vrsta medpomnilnika tipkovnice za shranjevanje tipk, ki jih pritisnejo uporabniki, in čakalna vrsta medpomnilnika tiskanja za shranjevanje dokumentov, ki jih natisne tiskalnik.
- Čakalne vrste so odgovorne za razporejanje procesorja, razporejanje opravil in razporejanje diska.
- Prioritetne čakalne vrste se uporabljajo pri operacijah prenosa datotek v brskalniku.
- Čakalne vrste se uporabljajo tudi za prenos podatkov med perifernimi napravami in CPE.
- Čakalne vrste so odgovorne tudi za obravnavanje prekinitev, ki jih ustvarijo uporabniške aplikacije za CPE.
Nelinearne podatkovne strukture
Nelinearne podatkovne strukture so podatkovne strukture, kjer podatkovni elementi niso urejeni v zaporednem vrstnem redu. Tukaj vstavljanje in odstranjevanje podatkov nista izvedljiva na linearen način. Med posameznimi podatki obstaja hierarhično razmerje.
Vrste nelinearnih podatkovnih struktur
Sledi seznam nelinearnih podatkovnih struktur, ki jih običajno uporabljamo:
1. Drevesa
Drevo je nelinearna podatkovna struktura in hierarhija, ki vsebuje zbirko vozlišč, tako da vsako vozlišče drevesa shrani vrednost in seznam referenc na druga vozlišča ('otroke').
Drevesna podatkovna struktura je specializirana metoda za urejanje in zbiranje podatkov v računalniku, da bi jih lahko učinkoviteje uporabili. Vsebuje osrednje vozlišče, strukturna vozlišča in podvozlišča, povezana preko robov. Lahko tudi rečemo, da drevesno podatkovno strukturo sestavljajo povezane korenine, veje in listi.

Slika 9. Drevo
niz podniz java
Drevesa lahko razdelimo na več vrst:
Nekatere uporabe dreves:
- Drevesa izvajajo hierarhične strukture v računalniških sistemih, kot so imeniki in datotečni sistemi.
- Drevesa se uporabljajo tudi za implementacijo navigacijske strukture spletnega mesta.
- Z drevesi lahko ustvarimo kodo, kot je Huffmanova koda.
- Drevesa so prav tako v pomoč pri odločanju v igralnih aplikacijah.
- Drevesa so odgovorna za izvajanje prednostnih čakalnih vrst za funkcije razporejanja OS, ki temeljijo na prioritetah.
- Drevesa so odgovorna tudi za razčlenjevanje izrazov in stavkov v prevajalnikih različnih programskih jezikov.
- Drevesa lahko uporabimo za shranjevanje podatkovnih ključev za indeksiranje za sistem za upravljanje baz podatkov (DBMS).
- Spanning Trees nam omogočajo usmerjanje odločitev v računalniških in komunikacijskih omrežjih.
- Drevesa se uporabljajo tudi v algoritmu za iskanje poti, implementiranem v aplikacije za umetno inteligenco (AI), robotiko in video igre.
2. Grafi
Graf je še en primer nelinearne podatkovne strukture, ki obsega končno število vozlišč ali oglišč in robov, ki jih povezujejo. Grafi se uporabljajo za reševanje problemov resničnega sveta, v katerem označujejo problemsko področje kot omrežje, kot so socialna omrežja, omrežja vezij in telefonska omrežja. Na primer, vozlišča ali oglišča grafa lahko predstavljajo enega uporabnika v telefonskem omrežju, medtem ko robovi predstavljajo povezavo med njimi prek telefona.
Podatkovna struktura Graph, G, velja za matematično strukturo, sestavljeno iz niza oglišč, V in niza robov, E, kot je prikazano spodaj:
G = (V,E)

Slika 10. Graf
Zgornja slika predstavlja graf s sedmimi vozlišči A, B, C, D, E, F, G in desetimi robovi [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] in [E, G].
Glede na položaj oglišč in robov lahko grafe razvrstimo v različne vrste:
Nekatere uporabe grafov:
- Grafi nam pomagajo predstavljati poti in omrežja v transportnih, potovalnih in komunikacijskih aplikacijah.
- Grafi se uporabljajo za prikaz poti v GPS.
- Grafi nam tudi pomagajo predstaviti medsebojne povezave v družbenih omrežjih in drugih omrežnih aplikacijah.
- Grafi se uporabljajo v aplikacijah za kartiranje.
- Grafi so odgovorni za predstavitev uporabniških preferenc v aplikacijah za e-trgovino.
- Grafi se uporabljajo tudi v komunalnih omrežjih za prepoznavanje težav, ki jih predstavljajo lokalne ali občinske družbe.
- Grafi pomagajo tudi pri upravljanju uporabe in razpoložljivosti virov v organizaciji.
- Grafi se uporabljajo tudi za izdelavo zemljevidov povezav dokumentov spletnih mest, da se prikaže povezljivost med stranmi prek hiperpovezav.
- Grafi se uporabljajo tudi pri robotskih gibanjih in nevronskih mrežah.
Osnovne operacije podatkovnih struktur
V naslednjem razdelku bomo razpravljali o različnih vrstah operacij, ki jih lahko izvedemo za manipulacijo podatkov v vsaki podatkovni strukturi:
- Čas prevajanja
- Čas izvajanja
Na primer, malloc() funkcija se uporablja v jeziku C za ustvarjanje strukture podatkov.
Razumevanje abstraktnega podatkovnega tipa
Glede na Nacionalni inštitut za standarde in tehnologijo (NIST) , podatkovna struktura je razporeditev informacij, običajno v pomnilniku, za boljšo učinkovitost algoritma. Podatkovne strukture vključujejo povezane sezname, sklade, čakalne vrste, drevesa in slovarje. Lahko so tudi teoretična entiteta, kot je ime in naslov osebe.
Iz zgoraj navedene definicije lahko sklepamo, da operacije v podatkovni strukturi vključujejo:
- Visoka raven abstrakcij, kot je dodajanje ali brisanje elementa s seznama.
- Iskanje in razvrščanje elementa na seznamu.
- Dostop do elementa z najvišjo prioriteto na seznamu.
Kadarkoli podatkovna struktura izvaja takšne operacije, je znana kot an Abstraktni podatkovni tip (ADT) .
upravitelj opravil za linux
Lahko ga definiramo kot niz podatkovnih elementov skupaj z operacijami na podatkih. Izraz 'abstrakten' se nanaša na dejstvo, da se podatki in temeljne operacije, definirane na njih, preučujejo neodvisno od njihove implementacije. Vključuje, kaj lahko naredimo s podatki, ne pa, kako lahko to storimo.
Izvedba ADI vsebuje pomnilniško strukturo za shranjevanje podatkovnih elementov in algoritmov za temeljno delovanje. Vse podatkovne strukture, kot so polje, povezani seznam, čakalna vrsta, sklad itd., so primeri ADT.
Razumevanje prednosti uporabe ADT
V resničnem svetu se programi razvijajo kot posledica novih omejitev ali zahtev, zato spreminjanje programa na splošno zahteva spremembo ene ali več podatkovnih struktur. Denimo, da želimo v evidenco zaposlenega vstaviti novo polje, da bi spremljali več podrobnosti o vsakem zaposlenem. V tem primeru lahko izboljšamo učinkovitost programa tako, da matriko nadomestimo s povezano strukturo. V takšni situaciji je ponovno pisanje vsakega postopka, ki uporablja spremenjeno strukturo, neprimerno. Zato je boljša alternativa ločiti podatkovno strukturo od informacij o njeni izvedbi. To je načelo za uporabo abstraktnih podatkovnih vrst (ADT).
Nekatere aplikacije podatkovnih struktur
Sledi nekaj aplikacij podatkovnih struktur:
- Podatkovne strukture pomagajo pri organizaciji podatkov v pomnilniku računalnika.
- Podatkovne strukture pomagajo tudi pri predstavljanju informacij v bazah podatkov.
- Podatkovne strukture omogočajo implementacijo algoritmov za iskanje po podatkih (na primer iskalnik).
- Podatkovne strukture lahko uporabimo za izvajanje algoritmov za manipulacijo podatkov (na primer urejevalniki besedil).
- Prav tako lahko implementiramo algoritme za analizo podatkov z uporabo podatkovnih struktur (na primer podatkovni rudarji).
- Podatkovne strukture podpirajo algoritme za ustvarjanje podatkov (na primer generator naključnih števil).
- Podatkovne strukture podpirajo tudi algoritme za stiskanje in dekompresijo podatkov (na primer pripomoček zip).
- Podatkovne strukture lahko uporabimo tudi za izvajanje algoritmov za šifriranje in dešifriranje podatkov (na primer varnostni sistem).
- S pomočjo podatkovnih struktur lahko zgradimo programsko opremo, ki lahko upravlja datoteke in imenike (na primer upravitelj datotek).
- Prav tako lahko razvijemo programsko opremo, ki lahko upodablja grafiko z uporabo podatkovnih struktur. (Na primer spletni brskalnik ali programska oprema za 3D upodabljanje).
Poleg teh, kot smo že omenili, obstaja veliko drugih aplikacij podatkovnih struktur, ki nam lahko pomagajo zgraditi želeno programsko opremo.