Excelovi listi so zelo instinktivni in uporabniku prijazni, zaradi česar so idealni za manipulacijo velikih podatkovnih nizov tudi za manj tehnične ljudi. Če iščete mesta, kjer bi se lahko naučili manipulirati in avtomatizirati stvari v Excelovih datotekah z uporabo Python , ne išči več. Na pravem ste mestu.
V tem članku se boste naučili uporabljati Pande za delo z Excelovimi preglednicami. V tem članku bomo spoznali:
- Preberi Excelova datoteka z uporabo Pand v Pythonu
- Namestitev in uvoz Pand
- Branje več Excelovih listov s programom Pandas
- Uporaba različnih funkcij Panda
Branje datoteke Excel z uporabo Pandas v Pythonu
Namestitev Pand
Za namestitev Pande v Python lahko uporabimo naslednji ukaz v ukaznem pozivu:
pip install pandas>
Za namestitev Pande v Anacondo lahko uporabimo naslednji ukaz v terminalu Anaconda:
conda install pandas>
Uvoz pand
Najprej moramo uvoziti modul Pandas, kar lahko storimo z zagonom ukaza:
Python3
import> pandas as pd> |
>
>
Vhodna datoteka: Recimo, da je Excelova datoteka videti takole
List 1:

List 1
List 2:
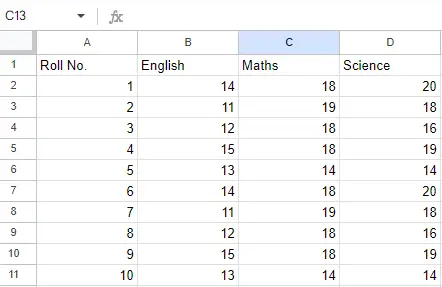
List 2
obravnavanje izjem v Javi
Zdaj lahko uvozimo Excelovo datoteko s funkcijo read_excel v Pandas za branje Excelove datoteke s Pandas v Pythonu. Drugi stavek prebere podatke iz Excela in jih shrani v podatkovni okvir pandas, ki ga predstavlja spremenljivka newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Izhod:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Nalaganje več listov z metodo Concat().
Če je v Excelovem delovnem zvezku več listov, bo ukaz uvozil podatke s prvega lista. Če želite ustvariti podatkovni okvir z vsemi listi v delovnem zvezku, je najlažji način, da ločeno ustvarite različne podatkovne okvire in jih nato povežete. Metoda read_excel sprejme argument sheet_name in index_col, kjer lahko določimo list, iz katerega naj bo sestavljen okvir, index_col pa poda naslovni stolpec, kot je prikazano spodaj:
primer:
Tretji stavek združuje oba lista. Zdaj, da preverimo celoten okvir podatkov, lahko preprosto zaženemo naslednji ukaz:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Izhod:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Metodi Head() in Tail() v Pandah
Če si želite ogledati 5 stolpcev od zgoraj in od spodaj podatkovnega okvira, lahko zaženemo ukaz. to glava() in rep () Metoda prav tako vzame argumente kot številke za število stolpcev za prikaz.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Izhod:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Metoda Shape().
The metoda shape(). lahko uporabite za ogled števila vrstic in stolpcev v podatkovnem okviru, kot sledi:
Python3
newData.shape> |
>
>
Izhod:
(20, 3)>
Metoda Sort_values() v Pandas
Če kateri koli stolpec vsebuje številske podatke, lahko ta stolpec razvrstimo z uporabo sort_values() metoda v pandah, kot sledi:
Python3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Zdaj pa predpostavimo, da želimo prvih 5 vrednosti razvrščenega stolpca, tukaj lahko uporabimo metodo head():
Python3
sorted_column.head(>5>)> |
>
>
Izhod:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
To lahko naredimo s katerim koli številčnim stolpcem podatkovnega okvira, kot je prikazano spodaj:
Python3
newData[>'Maths'>].head()> |
>
>
Izhod:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Metoda Pandas Describe().
Recimo, da so naši podatki večinoma numerični. Dobimo lahko statistične informacije, kot so povprečje, največ, najmanj itd. o podatkovnem okviru z uporabo opisati () metoda, kot je prikazano spodaj:
Python3
newData.describe()> |
>
>
Izhod:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
To lahko storite tudi ločeno za vse številske stolpce z naslednjim ukazom:
Python3
newData[>'English'>].mean()> |
>
>
Izhod:
14.3>
Z ustreznimi metodami je mogoče izračunati tudi druge statistične podatke. Tako kot v Excelu je mogoče uporabiti tudi formule in izračunane stolpce ustvariti na naslednji način:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
modifikacijske tipke
Izhod:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Po operaciji s podatki v podatkovnem okviru lahko podatke izvozimo nazaj v Excelovo datoteko z uporabo metode to_excel. Za to moramo podati izhodno Excelovo datoteko, kamor naj se zapišejo transformirani podatki, kot je prikazano spodaj:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Izhod:
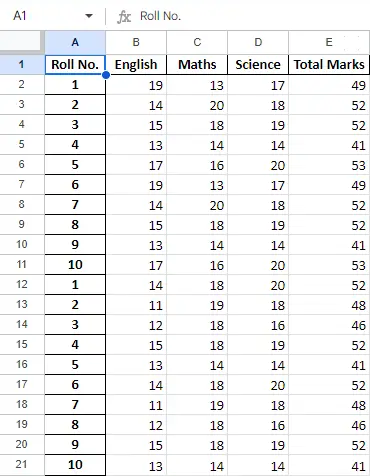
Končni list