Strojno učenje je veja Umetna inteligenca ki se osredotoča na razvoj modelov in algoritmov, ki računalnikom omogočajo, da se učijo iz podatkov in izboljšajo iz prejšnjih izkušenj, ne da bi bili izrecno programirani za vsako nalogo. Preprosto povedano, ML uči sisteme razmišljati in razumeti kot ljudje, tako da se učijo iz podatkov.
logično v niz
V tem članku bomo raziskali različne vrste algoritmi strojnega učenja ki so pomembne za prihodnje zahteve. Strojno učenje je na splošno sistem usposabljanja za učenje iz preteklih izkušenj in izboljšanje učinkovitosti skozi čas. Strojno učenje pomaga napovedati ogromne količine podatkov. Pomaga pri zagotavljanju hitrih in natančnih rezultatov za pridobitev donosnih priložnosti.
Vrste strojnega učenja
Obstaja več vrst strojnega učenja, od katerih ima vsaka posebne značilnosti in aplikacije. Nekatere glavne vrste algoritmov strojnega učenja so naslednje:
- Nadzorovano strojno učenje
- Nenadzorovano strojno učenje
- Polnadzorovano strojno učenje
- Okrepitveno učenje
Vrste strojnega učenja
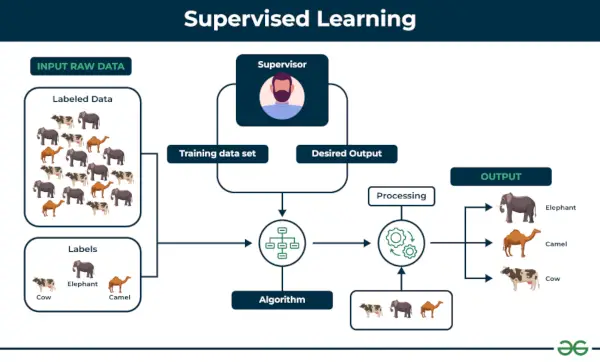
1. Nadzorovano strojno učenje
Učenje pod nadzorom je definirano, ko se model uri na a Označen nabor podatkov . Označeni nizi podatkov imajo vhodne in izhodne parametre. noter Nadzorovano učenje algoritmi se naučijo preslikati točke med vhodi in pravilnimi izhodi. Označene ima nabore podatkov za usposabljanje in validacijo.
Nadzorovano učenje
Razumejmo to s pomočjo primera.
primer: Razmislite o scenariju, kjer morate zgraditi klasifikator slik za razlikovanje med mačkami in psi. Če v algoritem vnesete nabore podatkov o slikah z oznako psov in mačk, se bo stroj naučil razvrščati med psom ali mačko iz teh označenih slik. Ko vnesemo nove slike psa ali mačke, ki jih še nikoli ni videl, bo uporabil naučene algoritme in predvidel, ali je pes ali mačka. Tako je nadzorovano učenje deluje, in to je zlasti klasifikacija slik.
Spodaj sta omenjeni dve glavni kategoriji nadzorovanega učenja:
- Razvrstitev
- Regresija
Razvrstitev
Razvrstitev ukvarja z napovedovanjem kategorično ciljne spremenljivke, ki predstavljajo diskretne razrede ali oznake. Na primer, razvrščanje e-poštnih sporočil med neželeno ali neželeno pošto ali napovedovanje, ali ima bolnik veliko tveganje za srčno bolezen. Klasifikacijski algoritmi se naučijo preslikati vhodne funkcije v enega od vnaprej določenih razredov.
Tukaj je nekaj algoritmov za razvrščanje:
- Logistična regresija
- Podporni vektorski stroj
- Naključni gozd
- Drevo odločitev
- K-najbližji sosedje (KNN)
- Naivni Bayes
Regresija
Regresija , pa se ukvarja s predvidevanjem neprekinjeno ciljne spremenljivke, ki predstavljajo numerične vrednosti. Na primer napovedovanje cene hiše na podlagi njene velikosti, lokacije in opreme ali napovedovanje prodaje izdelka. Regresijski algoritmi se naučijo preslikati vhodne značilnosti v zvezno številčno vrednost.
Tukaj je nekaj regresijskih algoritmov:
- Linearna regresija
- Polinomska regresija
- Grebenska regresija
- Regresija z lasom
- Odločitveno drevo
- Naključni gozd
Prednosti nadzorovanega strojnega učenja
- Nadzorovano učenje modeli imajo lahko visoko natančnost, ko se na njih učijo označeni podatki .
- Postopek odločanja v modelih nadzorovanega učenja je pogosto mogoče razlagati.
- Pogosto se lahko uporablja v vnaprej pripravljenih modelih, kar prihrani čas in sredstva pri razvoju novih modelov iz nič.
Slabosti nadzorovanega strojnega učenja
- Ima omejitve pri poznavanju vzorcev in se lahko spopada z nevidnimi ali nepričakovanimi vzorci, ki niso prisotni v podatkih o usposabljanju.
- Lahko je zamudno in drago, saj je odvisno od tega označeno samo podatki.
- To lahko povzroči slabe posplošitve na podlagi novih podatkov.
Aplikacije nadzorovanega učenja
Nadzorovano učenje se uporablja v številnih aplikacijah, vključno z:
- Klasifikacija slik : Prepoznajte predmete, obraze in druge značilnosti na slikah.
- Obdelava naravnega jezika: Iz besedila izvlecite informacije, kot so občutki, entitete in odnosi.
- Prepoznavanje govora : Pretvorite govorjeni jezik v besedilo.
- Priporočilni sistemi : Ustvarite prilagojena priporočila uporabnikom.
- Napovedna analitika : Predvidite rezultate, kot so prodaja, odliv strank in cene delnic.
- Medicinska diagnoza : Odkrijte bolezni in druga zdravstvena stanja.
- Odkrivanje goljufij : Prepoznajte goljufive transakcije.
- Avtonomna vozila : Prepoznavanje predmetov v okolju in odziv nanje.
- Zaznavanje vsiljene e-pošte : E-poštna sporočila razvrstite med vsiljeno pošto ali ne.
- Kontrola kakovosti v proizvodnji : Preglejte izdelke glede napak.
- Kreditno točkovanje : Ocenite tveganje, da posojilojemalec ne bo plačal posojila.
- Igranje : Prepoznajte like, analizirajte vedenje igralcev in ustvarite NPC-je.
- Pomoč strankam : Avtomatizirajte naloge podpore strankam.
- Napovedovanje vremena : Naredite napovedi za temperaturo, padavine in druge meteorološke parametre.
- Športna analitika : analizirajte uspešnost igralcev, naredite napovedi igre in optimizirajte strategije.
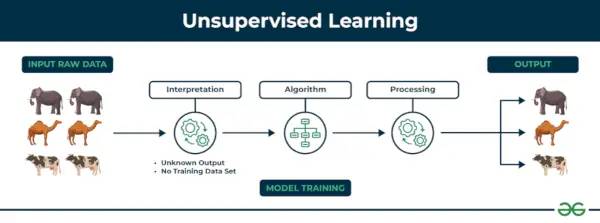
2. Nenadzorovano strojno učenje
Učenje brez nadzora Nenadzorovano učenje je vrsta tehnike strojnega učenja, pri kateri algoritem odkriva vzorce in razmerja z uporabo neoznačenih podatkov. Za razliko od nadzorovanega učenja nenadzorovano učenje ne vključuje zagotavljanja algoritma z označenimi ciljnimi izhodi. Primarni cilj nenadzorovanega učenja je pogosto odkrivanje skritih vzorcev, podobnosti ali grozdov v podatkih, ki jih je nato mogoče uporabiti za različne namene, kot so raziskovanje podatkov, vizualizacija, zmanjšanje dimenzionalnosti in drugo.
pretvori int v niz v javi
Učenje brez nadzora
Razumejmo to s pomočjo primera.
primer: Predpostavljajte, da imate nabor podatkov, ki vsebuje informacije o nakupih, ki ste jih opravili v trgovini. Z združevanjem v gruče lahko algoritem združi enako nakupovalno vedenje med vami in drugimi strankami, kar razkrije potencialne stranke brez vnaprej določenih oznak. Ta vrsta informacij lahko pomaga podjetjem pridobiti ciljne stranke in prepoznati odstopanja.
Spodaj sta omenjeni dve glavni kategoriji nenadzorovanega učenja:
- Grozdenje
- Združenje
Grozdenje
Grozdenje je postopek združevanja podatkovnih točk v skupine na podlagi njihove podobnosti. Ta tehnika je uporabna za prepoznavanje vzorcev in odnosov v podatkih brez potrebe po označenih primerih.
Tukaj je nekaj algoritmov za združevanje v gruče:
- Algoritem združevanja v skupine K-Means
- Algoritem srednjega premika
- Algoritem DBSCAN
- Analiza glavnih komponent
- Neodvisna analiza komponent
Združenje
Asociacijsko pravilo se nauči ing je tehnika za odkrivanje odnosov med elementi v naboru podatkov. Identificira pravila, ki kažejo na prisotnost enega elementa, kar implicira prisotnost drugega elementa z določeno verjetnostjo.
Tukaj je nekaj algoritmov učenja asociacijskih pravil:
- Apriorni algoritem
- Sijaj
- FP-algoritem rasti
Prednosti nenadzorovanega strojnega učenja
- Pomaga pri odkrivanju skritih vzorcev in različnih odnosov med podatki.
- Uporablja se za naloge, kot je npr segmentacija strank, odkrivanje nepravilnosti, in raziskovanje podatkov .
- Ne zahteva označenih podatkov in zmanjša napor označevanja podatkov.
Slabosti nenadzorovanega strojnega učenja
- Brez uporabe oznak bo morda težko napovedati kakovost izpisa modela.
- Razlagalnost gruče morda ni jasna in morda nima smiselnih interpretacij.
- Ima tehnike, kot je npr avtokodirniki in zmanjšanje dimenzionalnosti ki jih je mogoče uporabiti za pridobivanje pomembnih funkcij iz neobdelanih podatkov.
Aplikacije nenadzorovanega učenja
Tukaj je nekaj pogostih aplikacij nenadzorovanega učenja:
- Grozdenje : Združi podobne podatkovne točke v gruče.
- Odkrivanje anomalij : Prepoznajte odstopanja ali anomalije v podatkih.
- Zmanjšanje dimenzij : Zmanjšajte dimenzionalnost podatkov, hkrati pa ohranite njihove bistvene informacije.
- Priporočilni sistemi : uporabnikom predlagajte izdelke, filme ali vsebino na podlagi njihovega zgodovinskega vedenja ali preferenc.
- Modeliranje teme : Odkrijte skrite teme v zbirki dokumentov.
- Ocena gostote : Ocenite funkcijo gostote verjetnosti podatkov.
- Kompresija slike in videa : Zmanjšajte količino prostora za shranjevanje večpredstavnostnih vsebin.
- Predobdelava podatkov : Pomoč pri opravilih predprocesiranja podatkov, kot je čiščenje podatkov, imputacija manjkajočih vrednosti in skaliranje podatkov.
- Analiza tržne košarice : Odkrijte povezave med izdelki.
- Analiza genomskih podatkov : Identificirajte vzorce ali združite gene s podobnimi profili izražanja.
- Segmentacija slike : Segmentirajte slike v pomembne regije.
- Zaznavanje skupnosti v družbenih omrežjih : Identificirajte skupnosti ali skupine posameznikov s podobnimi interesi ali povezavami.
- Analiza vedenja strank : Odkrijte vzorce in vpoglede za boljše trženje in priporočila za izdelke.
- Vsebinsko priporočilo : Razvrstite in označite vsebino, da boste uporabnikom lažje priporočali podobne predmete.
- Raziskovalna analiza podatkov (EDA) : Raziščite podatke in pridobite vpogled, preden definirate določene naloge.
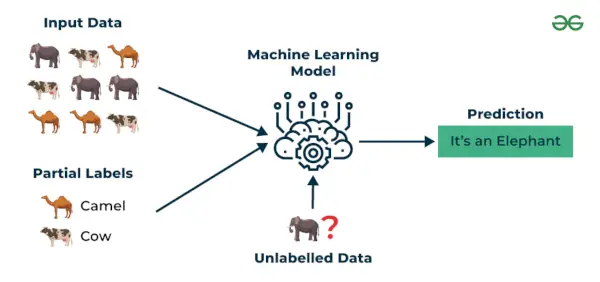
3. Polnadzorovano učenje
Polnadzorovano učenje je algoritem strojnega učenja, ki deluje med nadzorovano in nenadzorovano učenja, tako da uporablja oboje označeni in neoznačeni podatke. To je še posebej uporabno, kadar je pridobivanje označenih podatkov drago, dolgotrajno ali zahteva veliko virov. Ta pristop je uporaben, kadar je nabor podatkov drag in dolgotrajen. Delno nadzorovano učenje je izbrano, kadar označeni podatki zahtevajo spretnosti in ustrezne vire za usposabljanje ali učenje iz njih.
Te tehnike uporabljamo, ko imamo opravka s podatki, ki so malo označeni, preostali velik del pa je neoznačen. Nenadzorovane tehnike lahko uporabimo za napovedovanje oznak in nato te oznake posredujemo nadzorovanim tehnikam. Ta tehnika je večinoma uporabna v primeru nizov slikovnih podatkov, kjer običajno vse slike niso označene.
Polnadzorovano učenje
Razumejmo to s pomočjo primera.
Primer : Upoštevajte, da gradimo jezikovni prevajalski model, saj lahko označeni prevodi za vsak stavčni par zahtevajo veliko virov. Modelom omogoča učenje iz označenih in neoznačenih parov stavkov, zaradi česar so bolj natančni. Ta tehnika je privedla do pomembnih izboljšav kakovosti storitev strojnega prevajanja.
Vrste delno nadzorovanih učnih metod
Obstaja več različnih delno nadzorovanih učnih metod, od katerih ima vsaka svoje značilnosti. Nekateri najpogostejši vključujejo:
java povratni niz
- Polnadzorovano učenje na osnovi grafov: Ta pristop uporablja graf za predstavitev odnosov med podatkovnimi točkami. Graf se nato uporabi za širjenje oznak od označenih podatkovnih točk do neoznačenih podatkovnih točk.
- Širjenje etikete: Ta pristop iterativno širi oznake od označenih podatkovnih točk do neoznačenih podatkovnih točk na podlagi podobnosti med podatkovnimi točkami.
- Ko-trening: Ta pristop usposablja dva različna modela strojnega učenja na različnih podmnožicah neoznačenih podatkov. Oba modela se nato uporabita za označevanje napovedi drug drugega.
- Samotrening: Ta pristop uri model strojnega učenja na označenih podatkih in nato uporabi model za predvidevanje oznak za neoznačene podatke. Model se nato ponovno usposobi za označene podatke in predvidene oznake za neoznačene podatke.
- Generativna kontradiktorna omrežja (GAN) : GAN-ji so vrsta algoritma globokega učenja, ki se lahko uporablja za ustvarjanje sintetičnih podatkov. GAN-je je mogoče uporabiti za ustvarjanje neoznačenih podatkov za delno nadzorovano učenje z usposabljanjem dveh nevronskih mrež, generatorja in diskriminatorja.
Prednosti delno nadzorovanega strojnega učenja
- Vodi k boljši generalizaciji v primerjavi z nadzorovano učenje, saj zajema tako označene kot neoznačene podatke.
- Uporablja se lahko za širok spekter podatkov.
Slabosti delno nadzorovanega strojnega učenja
- Polnadzorovano metode so lahko bolj zapletene za izvajanje v primerjavi z drugimi pristopi.
- Še vedno zahteva nekaj označeni podatki ki morda niso vedno na voljo ali jih je enostavno dobiti.
- Neoznačeni podatki lahko ustrezno vplivajo na delovanje modela.
Aplikacije delno nadzorovanega učenja
Tukaj je nekaj pogostih aplikacij delno nadzorovanega učenja:
- Klasifikacija slik in prepoznavanje objektov : Izboljšajte natančnost modelov s kombiniranjem majhnega nabora označenih slik z večjim naborom neoznačenih slik.
- Obdelava naravnega jezika (NLP) : Izboljšajte delovanje jezikovnih modelov in klasifikatorjev s kombiniranjem majhnega nabora označenih besedilnih podatkov z veliko količino neoznačenega besedila.
- Prepoznavanje govora: Izboljšajte natančnost prepoznavanja govora z uporabo omejene količine prepisanih govornih podatkov in obsežnejšega nabora neoznačenega zvoka.
- Priporočilni sistemi : Izboljšajte natančnost prilagojenih priporočil z dopolnitvijo redkega nabora interakcij med uporabniki in predmeti (označenih podatkov) z množico neoznačenih podatkov o vedenju uporabnikov.
- Zdravstveno varstvo in medicinsko slikanje : Izboljšajte analizo medicinskih slik z uporabo majhnega niza označenih medicinskih slik poleg večjega niza neoznačenih slik.
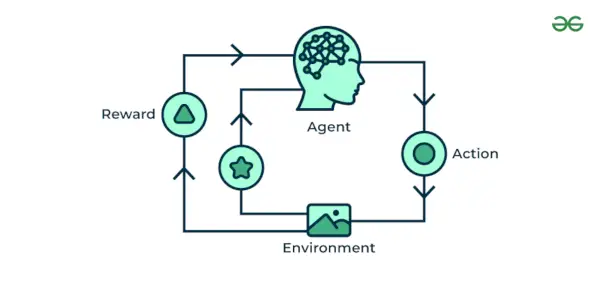
4. Okrepitveno strojno učenje
Okrepitveno strojno učenje algoritem je učna metoda, ki sodeluje z okoljem tako, da proizvaja dejanja in odkriva napake. Poskus, napaka in zamuda so najpomembnejše značilnosti učenja s krepitvijo. Pri tej tehniki model še naprej povečuje svojo zmogljivost z uporabo povratnih informacij o nagradi, da se nauči vedenja ali vzorca. Ti algoritmi so specifični za določen problem, npr. Google Self Driving car, AlphaGo, kjer bot tekmuje z ljudmi in celo s samim seboj, da bi bil vedno boljši v igri Go Game. Vsakič, ko vnašamo podatke, se učijo in dodajajo podatke svojemu znanju, ki so podatki za usposabljanje. Torej, več ko se uči, bolje je usposobljen in s tem izkušen.
Tu je nekaj najpogostejših algoritmov učenja za krepitev:
- Q-učenje: Q-learning je algoritem RL brez modela, ki se nauči Q-funkcije, ki preslika stanja v dejanja. Q-funkcija oceni pričakovano nagrado za izvedbo določenega dejanja v danem stanju.
- SARSA (State-Action-Reward-State-Action): SARSA je še en algoritem RL brez modela, ki se uči Q-funkcije. Vendar za razliko od Q-learninga SARSA posodobi Q-funkcijo za dejanje, ki je bilo dejansko izvedeno, namesto za optimalno dejanje.
- Globoko Q-učenje : Deep Q-learning je kombinacija Q-learninga in globokega učenja. Globoko Q-učenje uporablja nevronsko mrežo za predstavitev Q-funkcije, ki omogoča učenje zapletenih odnosov med stanji in dejanji.
Okrepitveno strojno učenje
Razumejmo to s pomočjo primerov.
primer: Upoštevajte, da trenirate an AI agent za igranje igre, kot je šah. Agent raziskuje različne poteze in glede na rezultat prejme pozitivne ali negativne povratne informacije. Reinforcement Learning najde tudi aplikacije, v katerih se učijo opravljati naloge z interakcijo z okolico.
Vrste ojačitvenega strojnega učenja
Obstajata dve glavni vrsti učenja s krepitvijo:
Pozitivna okrepitev
- Nagradi agenta za želeno dejanje.
- Spodbuja agenta, da ponovi vedenje.
- Primeri: dajanje priboljška psu za sedenje, zagotavljanje točke v igri za pravilen odgovor.
Negativna ojačitev
- Odstrani neželen dražljaj, da spodbudi želeno vedenje.
- Agenta odvrača od ponavljanja vedenja.
- Primeri: izklop glasnega brenčala ob pritisku na ročico, izogibanje kazni z dokončanjem naloge.
Prednosti okrepljenega strojnega učenja
- Ima avtonomno odločanje, ki je zelo primerno za naloge in se lahko nauči sprejemati zaporedje odločitev, kot sta robotika in igranje iger.
- Ta tehnika je prednostna za doseganje dolgoročnih rezultatov, ki jih je zelo težko doseči.
- Uporablja se za reševanje kompleksnih problemov, ki jih ni mogoče rešiti s konvencionalnimi tehnikami.
Slabosti okrepljenega strojnega učenja
- Training Reinforcement Učni agenti so lahko računsko dragi in zamudni.
- Učenje s krepitvijo ni boljše od reševanja preprostih problemov.
- Potrebuje veliko podatkov in veliko računanja, zaradi česar je nepraktičen in drag.
Aplikacije okrepljenega strojnega učenja
Tukaj je nekaj aplikacij učenja s krepitvijo:
- Igranje igre : RL lahko agente nauči igrati igre, tudi zapletene.
- Robotika : RL lahko nauči robote samostojnega opravljanja nalog.
- Avtonomna vozila : RL lahko samovozečim avtomobilom pomaga pri navigaciji in sprejemanju odločitev.
- Priporočilni sistemi : RL lahko izboljša algoritme priporočil z učenjem uporabniških preferenc.
- Skrb za zdravje : RL se lahko uporablja za optimizacijo načrtov zdravljenja in odkrivanje zdravil.
- Obdelava naravnega jezika (NLP) : RL se lahko uporablja v sistemih za dialog in klepetalnih robotih.
- Finance in trgovanje : RL se lahko uporablja za algoritemsko trgovanje.
- Upravljanje dobavne verige in zalog : RL se lahko uporablja za optimizacijo delovanja dobavne verige.
- Upravljanje z energijo : RL se lahko uporablja za optimizacijo porabe energije.
- Igre z umetno inteligenco : RL se lahko uporablja za ustvarjanje bolj inteligentnih in prilagodljivih NPC-jev v video igrah.
- Prilagodljivi osebni asistenti : RL se lahko uporablja za izboljšanje osebnih asistentov.
- Navidezna resničnost (VR) in razširjena resničnost (AR): RL je mogoče uporabiti za ustvarjanje poglobljenih in interaktivnih izkušenj.
- Industrijski nadzor : RL se lahko uporablja za optimizacijo industrijskih procesov.
- izobraževanje : RL se lahko uporablja za ustvarjanje prilagodljivih učnih sistemov.
- Kmetijstvo : RL se lahko uporablja za optimizacijo kmetijskih operacij.
Morate preveriti, naš podroben članek o : Algoritmi strojnega učenja
Zaključek
Skratka, vsaka vrsta strojnega učenja služi svojemu namenu in prispeva k splošni vlogi pri razvoju izboljšanih zmožnosti napovedovanja podatkov ter lahko spremeni različne industrije, kot je Podatkovna znanost . Pomaga pri obsežni proizvodnji podatkov in upravljanju naborov podatkov.
Vrste strojnega učenja – pogosta vprašanja
1. S kakšnimi izzivi se soočate pri nadzorovanem učenju?
Nekateri izzivi, s katerimi se srečujejo pri nadzorovanem učenju, v glavnem vključujejo obravnavanje razrednih neravnovesij, visokokakovostne označene podatke in izogibanje prekomernemu opremljanju, kjer modeli slabo delujejo na podatkih v realnem času.
psevdokoda java
2. Kje lahko uporabimo nadzorovano učenje?
Nadzorovano učenje se pogosto uporablja za naloge, kot je analiza vsiljene e-pošte, prepoznavanje slik in analiza razpoloženja.
3. Kakšna je prihodnost strojnega učenja?
Strojno učenje kot prihodnost lahko deluje na področjih, kot so analiza vremena ali podnebja, zdravstveni sistemi in avtonomno modeliranje.
4. Katere so različne vrste strojnega učenja?
Obstajajo tri glavne vrste strojnega učenja:
- Učenje pod nadzorom
- Učenje brez nadzora
- Učenje s krepitvijo
5. Kateri so najpogostejši algoritmi strojnega učenja?
Nekateri najpogostejši algoritmi strojnega učenja vključujejo:
- Linearna regresija
- Logistična regresija
- Podporni vektorski stroji (SVM)
- K-najbližji sosedje (KNN)
- Odločitvena drevesa
- Naključni gozdovi
- Umetne nevronske mreže