Ukaz Linux uniq se uporablja za odstranitev vseh ponovljenih vrstic iz datoteke. Uporablja se lahko tudi za prikaz števila poljubnih besed, samo ponovljenih vrstic, prezrtje znakov in primerjavo določenih polj. Je eden najpogosteje uporabljenih ukazov v Linux sistem. Pogosto se uporablja z razvrsti ukaz ker primerja sosednje znake. Zavrže vse enake vrstice in zapiše izhod.
Sintaksa:
uniq [OPTION]... [INPUT [OUTPUT]]
Opcije:
Nekatere uporabne možnosti ukazne vrstice ukaza uniq so naslednje:
-c, --štetje: pred vrsticami postavi število pojavitev.
-d, --ponovljeno: uporablja se za tiskanje podvojenih vrstic, po eno za vsako skupino.
-D: Uporablja se za tiskanje vseh podvojenih vrstic.
--vse ponovljeno[=METODA]: Je precej podobna možnosti '-D', razlika med obema možnostma je v tem, da omogoča ločevanje skupin s prazno vrstico.
kaj je prolog
-f, --skip-fields=N: Uporablja se za izogibanje primerjavi prvih N polj.
10 ml do oz
--group[=METOD]: Uporablja se za prikaz vseh elementov in ločuje skupine s prazno vrstico.
-i, --ignore-case: Uporablja se za ignoriranje razlik med primerjavo.
-s, --skip-chars=N: Uporablja se za izogibanje primerjavi prvih N znakov.
-u, --edinstveno: uporablja se za tiskanje edinstvenih vrstic.
-z, --končano z ničlo: Uporablja se za ločilo vrstic, ki je NUL in ni način nove vrstice.
-w, --check-chars=N: Uporablja se za primerjavo največ N znakov v vrsticah.
--pomoč: Uporablja se za prikaz dokumentacije pomoči.
--različica: Uporablja se za prikaz informacij o različici.
Primeri ukaza uniq
Oglejmo si naslednje primere ukaza uniq:
- Odstranite ponavljajoče se vrstice
- prešteti število pojavitev besede
- Prikaži ponovljene vrstice
- Prikažite edinstvene vrstice
- Zanemarjanje znakov v primerjavi
- Zanemarjanje polj pri primerjavi
Odstranite ponavljajoče se vrstice
Če želite odstraniti ponavljajoče se vrstice iz datoteke, izvedite osnovni ukaz uniq, kot sledi:
java util datum
sort dupli.txt | uniq
Zgornji ukaz bo odstranil podvojene vrstice iz datoteke 'dupli.txt'. Razmislite o spodnjem rezultatu:
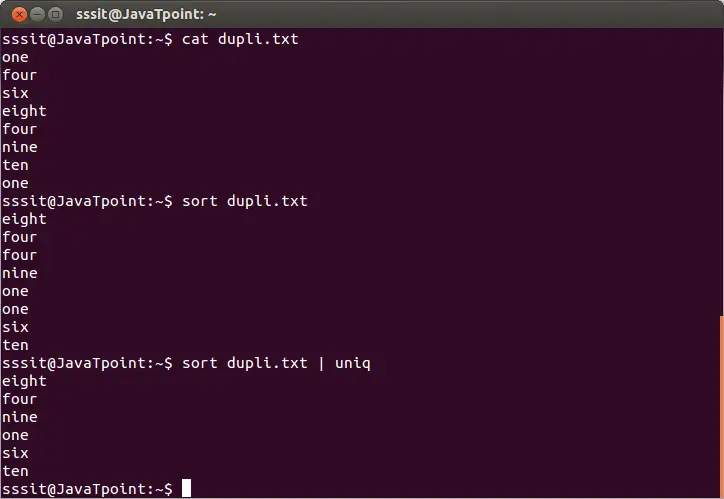
Iz zgornjega rezultata so ponavljajoče se besede prezrte.
Preštejte število pojavitev besede
Z ukazom uniq lahko preštejemo število pojavitev besede. Možnost '-c' se uporablja za štetje besede. Izvedite ga na naslednji način:
sort dupli.txt | uniq -c
Zgornji ukaz bo preštel besede, ki pridejo v 'dupli.txt'. Razmislite o spodnjem rezultatu:

Iz zgornjega izhoda je ukaz 'sort dupli.txt | uniq -c' šteje, kolikokrat se beseda ponovi.
Prikaži ponovljene vrstice
Možnost '-d' se uporablja za prikaz samo ponovljenih vrstic. Prikazal bo samo vrstice, ki bodo več kot enkrat v datoteki, in zapisal izhod v standardni izhod. Razmislite o spodnjem ukazu:
vadnica za selen
sort dupli.txt | uniq -d
Zgornji ukaz bo prikazal samo ponovljene vrstice. Razmislite o spodnjem rezultatu:

Prikažite edinstvene vrstice
Možnost '-u' se uporablja za prikaz samo edinstvenih vrstic (ki se ne ponavljajo). Prikazal bo le vrstice, ki se pojavijo samo enkrat, in rezultat zapisal v standardni izhod. Razmislite o spodnjem ukazu:
sort dupli.txt | uniq -u
Zgornji ukaz bo prikazal samo edinstvene vrstice iz datoteke 'dupli.txt'. Razmislite o spodnjem rezultatu:
tojson java

Zanemarjanje znakov v primerjavi
Možnost '-s' se uporablja za prezrtje znakov v primerjavi. Prezrl bo določeno število znakov in rezultat prikazal v standardnem izpisu. Razmislite o spodnjem ukazu:
sort dupli.txt | uniq -s 2
Zgornji ukaz bo prezrl prva dva znaka v primerjavi iz datoteke 'dupli.txt'. Razmislite o spodnjem rezultatu:

Zanemarjanje polj pri primerjavi
Možnost '-f' se uporablja za prezrtje polj. Razmislite o spodnjem ukazu:
uniq -f 2 dupli2.txt
Zgornji ukaz ne bo primerjal prvih dveh polj iz datoteke 'dupli2.txt'. Razmislite o spodnjem rezultatu:

Iz zgornjega izhoda sta prvi dve polji preskočeni, preostala vsa polja pa se primerjajo iz datoteke 'dupli2.txt'.