Uvod:
Skrajševalci URL-jev so primer zgoščevanja, saj preslikajo velike URL-je v majhne
Nekaj primerov zgoščevalnih funkcij:
- ključ % število veder
- ASCII vrednost znaka * PrimeNumberx. Kjer je x = 1, 2, 3….n
- Ustvarite lahko svojo lastno zgoščevalno funkcijo, vendar mora biti dobra zgoščevalna funkcija, ki zagotavlja manjše število kolizij.
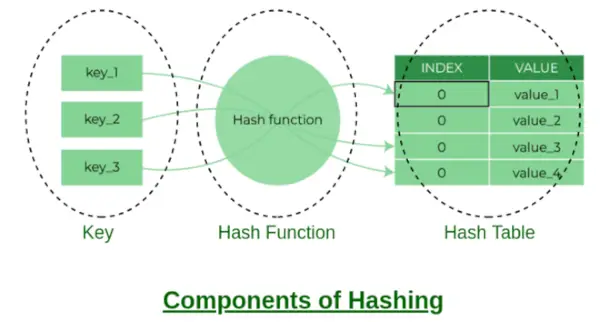
Komponente zgoščevanja
nespremenljiv seznam
Indeks vedra:
Vrednost, ki jo vrne funkcija Hash, je indeks vedra za ključ v ločeni metodi veriženja. Vsak indeks v matriki se imenuje vedro, saj je vedro povezanega seznama.
Preoblikovanje:
Ponovno zgoščevanje je koncept, ki zmanjša kolizijo, ko se elementi v trenutni zgoščevalni tabeli povečajo. Izdelal bo novo matriko podvojene velikosti in vanj kopiral prejšnje elemente matrike in je kot notranje delovanje vektorja v C++. Očitno bi morala biti funkcija Hash dinamična, saj bi morala odražati nekatere spremembe, ko se zmogljivost poveča. Zgoščevalna funkcija vključuje kapaciteto zgoščevalne tabele, zato med kopiranjem ključnih vrednosti iz prejšnje matrike zgoščevalna funkcija daje različne indekse vedra, saj je odvisna od zmogljivosti (vedra) zgoščevalne tabele. Običajno, ko je vrednost faktorja obremenitve večja od 0,5, se izvedejo ponovna izračunavanja.
- Podvojite velikost niza.
- Kopirajte elemente prejšnje matrike v novo matriko. Med ponovnim kopiranjem vsakega vozlišča v novo polje uporabljamo funkcijo zgoščevanja, kar bo zmanjšalo kolizijo.
- Izbrišite prejšnjo matriko iz pomnilnika in usmerite notranji kazalec matrike vašega razpršenega zemljevida na to novo matriko.
- Na splošno je faktor obremenitve = število elementov v razpršenem zemljevidu / skupno število veder (kapaciteta).
Trk:
Trk je situacija, ko indeks vedra ni prazen. To pomeni, da je v tem indeksu vedra prisotna povezana glava seznama. Imamo dve ali več vrednosti, ki se preslikajo v isti indeks vedra.
Glavne funkcije v našem programu
- Vstavljanje
- Iskanje
- Funkcija zgoščevanja
- Izbriši
- Preoblikovanje
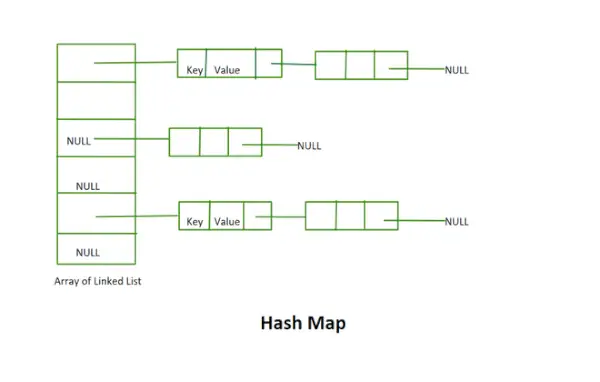
Hash Map
Izvedba brez preoblikovanja:
C
#include> #include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value)> {> >node->ključ = ključ;> >node->vrednost = vrednost;> >node->naslednji = NULL;> >return>;> };> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp)> {> >// Default capacity in this case> >mp->zmogljivost = 100;> >mp->numOfElements = 0;> >// array of size = 1> >mp->arr = (>struct> node**)>malloc>(>sizeof>(>struct> node*)> >* mp->zmogljivost);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key)> {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->zmogljivost)>> >+ (((>int>)key[i]) * factor) % mp->zmogljivost)>> >% mp->zmogljivost;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__)> >* (31 % __INT16_MAX__))> >% __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value)> {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = newNode;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->naslednji = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = newNode;> >}> >return>;> }> void> delete> (>struct> hashMap* mp,>char>* key)> {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->ključ) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->next;> >}> >// Last node or middle node> >else> {> >prevNode->naslednji = currNode->next;> >}> >free>(currNode);> >break>;> >}> >prevNode = currNode;> >currNode = currNode->naslednji;> >}> >return>;> }> char>* search(>struct> hashMap* mp,>char>* key)> {> >// Getting the bucket index> >// for the given key> >int> bucketIndex = hashFunction(mp, key);> >// Head of the linked list> >// present at bucket index> >struct> node* bucketHead = mp->arr[bucketIndex];> >while> (bucketHead != NULL) {> >// Key is found in the hashMap> >if> (bucketHead->tipka == tipka) {> >return> bucketHead->vrednost;> >}> >bucketHead = bucketHead->naslednji;> >}> >// If no key found in the hashMap> >// equal to the given key> >char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> >errorMssg =>'Oops! No data found.
'>;> >return> errorMssg;> }> // Drivers code> int> main()> {> >// Initialize the value of mp> >struct> hashMap* mp> >= (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> >initializeHashMap(mp);> >insert(mp,>'Yogaholic'>,>'Anjali'>);> >insert(mp,>'pluto14'>,>'Vartika'>);> >insert(mp,>'elite_Programmer'>,>'Manish'>);> >insert(mp,>'GFG'>,>'techcodeview.com'>);> >insert(mp,>'decentBoy'>,>'Mayank'>);> >printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> >printf>(>'%s
'>, search(mp,>'Yogaholic'>));> >printf>(>'%s
'>, search(mp,>'pluto14'>));> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >printf>(>'%s
'>, search(mp,>'GFG'>));> >// Key is not inserted> >printf>(>'%s
'>, search(mp,>'randomKey'>));> >printf>(>'
After deletion :
'>);> >// Deletion of key> >delete> (mp,>'decentBoy'>);> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >return> 0;> }> |
>
>
C++
#include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value) {> >node->ključ = ključ;> >node->vrednost = vrednost;> >node->naslednji = NULL;> >return>;> }> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp) {> >// Default capacity in this case> >mp->zmogljivost = 100;> >mp->numOfElements = 0;> >// array of size = 1> >mp->arr = (>struct> node**)>malloc>(>sizeof>(>struct> node*) * mp->zmogljivost);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key) {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->zmogljivost) + (((>int>)key[i]) * factor) % mp->kapaciteta) % mp->kapaciteta;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value) {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = newNode;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->naslednji = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = newNode;> >}> >return>;> }> void> deleteKey(>struct> hashMap* mp,>char>* key) {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->ključ) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->next;> >}> >// Last node or middle node> >else> {> >prevNode->naslednji = currNode->next;> }> free>(currNode);> break>;> }> prevNode = currNode;> >currNode = currNode->naslednji;> >}> return>;> }> char>* search(>struct> hashMap* mp,>char>* key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[bucketIndex];> while> (bucketHead != NULL) {> > >// Key is found in the hashMap> >if> (>strcmp>(bucketHead->ključ, ključ) == 0) {> >return> bucketHead->vrednost;> >}> > >bucketHead = bucketHead->naslednji;> }> // If no key found in the hashMap equal to the given key> char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> strcpy>(errorMssg,>'Oops! No data found.
'>);> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> initializeHashMap(mp);> insert(mp,>'Yogaholic'>,>'Anjali'>);> insert(mp,>'pluto14'>,>'Vartika'>);> insert(mp,>'elite_Programmer'>,>'Manish'>);> insert(mp,>'GFG'>,>'techcodeview.com'>);> insert(mp,>'decentBoy'>,>'Mayank'>);> printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> printf>(>'%s
'>, search(mp,>'Yogaholic'>));> printf>(>'%s
'>, search(mp,>'pluto14'>));> printf>(>'%s
'>, search(mp,>'decentBoy'>));> printf>(>'%s
'>, search(mp,>'GFG'>));> // Key is not inserted> printf>(>'%s
'>, search(mp,>'randomKey'>));> printf>(>'
After deletion :
'>);> // Deletion of key> deleteKey(mp,>'decentBoy'>);> // Searching the deleted key> printf>(>'%s
'>, search(mp,>'decentBoy'>));> return> 0;> }> |
>
seznam polj java
>Izhod
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.>
Pojasnilo:
- vstavljanje: Vstavi par ključ-vrednost na čelo povezanega seznama, ki je prisoten v danem indeksu vedra. hashFunction: poda indeks vedra za dani ključ. Naš zgoščevalna funkcija = ASCII vrednost znaka * praštevilox . Praštevilo v našem primeru je 31 in vrednost x narašča od 1 do n za zaporedne znake v ključu. izbris: Izbriše par ključ-vrednost iz zgoščene tabele za dani ključ. Izbriše vozlišče s povezanega seznama, ki vsebuje par ključ-vrednost. Iskanje: poiščite vrednost danega ključa.
- Ta izvedba ne uporablja koncepta preoblikovanja. Je niz povezanih seznamov fiksne velikosti.
- V danem primeru sta ključ in vrednost niza.
Časovna kompleksnost in prostorska kompleksnost:
Časovna zahtevnost operacij vstavljanja in brisanja razpršilne tabele je v povprečju O(1). Obstaja nekaj matematičnega izračuna, ki to dokazuje.
- Časovna zahtevnost vstavljanja: V povprečnem primeru je konstantna. V najslabšem primeru je linearna. Časovna zahtevnost iskanja: V povprečnem primeru je konstantna. V najslabšem primeru je linearna. Časovna zahtevnost izbrisa: V povprečnih primerih je konstantna. V najslabšem primeru je linearna. Kompleksnost prostora: O(n), saj ima n elementov.
Povezani članki:
- Ločena tehnika obravnavanja trkov pri verižnem zgoščevanju.