Zgoščeni zemljevidi so indeksirane podatkovne strukture. Zgoščeni zemljevid uporablja a hash funkcija za izračun indeksa s ključem v niz veder ali rež. Njegova vrednost je preslikana v vedro z ustreznim indeksom. Ključ je edinstven in nespremenljiv. Razpršilni zemljevid si predstavljajte kot omaro s predali z oznakami za stvari, ki so v njih shranjene. Na primer shranjevanje podatkov o uporabniku – upoštevajte e-pošto kot ključ in vrednosti, ki ustrezajo temu uporabniku, kot so ime, priimek itd., lahko preslikamo v vedro.
Zgoščevalna funkcija je jedro implementacije zgoščenega zemljevida. Prevzame ključ in ga prevede v indeks segmenta na seznamu segmentov. Idealno zgoščevanje bi moralo ustvariti drugačen indeks za vsak ključ. Lahko pa pride do kolizij. Ko zgoščevanje poda obstoječi indeks, lahko preprosto uporabimo vedro za več vrednosti, tako da dodamo seznam ali ponovno zgostimo.
V Pythonu so slovarji primeri zgoščenih zemljevidov. Videli bomo implementacijo zgoščene karte iz nič, da se naučimo, kako zgraditi in prilagoditi take podatkovne strukture za optimizacijo iskanja.
char v int java
Zasnova zgoščenega zemljevida bo vključevala naslednje funkcije:
- set_val(ključ, vrednost): V zgoščeno preslikavo vstavi par ključ-vrednost. Če vrednost že obstaja v razpršenem zemljevidu, posodobite vrednost.
- get_val(ključ): Vrne vrednost, v katero je preslikan podani ključ, ali Zapis ni bil najden, če ta preslikava ne vsebuje preslikave za ključ.
- delete_val(ključ): Odstrani preslikavo za določen ključ, če zgoščena preslikava vsebuje preslikavo za ključ.
Spodaj je izvedba.
Python3
selenium tutorial java
class> HashTable:> ># Create empty bucket list of given size> >def> __init__(>self>, size):> >self>.size>=> size> >self>.hash_table>=> self>.create_buckets()> >def> create_buckets(>self>):> >return> [[]>for> _>in> range>(>self>.size)]> ># Insert values into hash map> >def> set_val(>self>, key, val):> > ># Get the index from the key> ># using hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be inserted> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key to be inserted,> ># Update the key value> ># Otherwise append the new key-value pair to the bucket> >if> found_key:> >bucket[index]>=> (key, val)> >else>:> >bucket.append((key, val))> ># Return searched value with specific key> >def> get_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key being searched> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key being searched,> ># Return the value found> ># Otherwise indicate there was no record found> >if> found_key:> >return> record_val> >else>:> >return> 'No record found'> ># Remove a value with specific key> >def> delete_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be deleted> >if> record_key>=>=> key:> >found_key>=> True> >break> >if> found_key:> >bucket.pop(index)> >return> ># To print the items of hash map> >def> __str__(>self>):> >return> ''.join(>str>(item)>for> item>in> self>.hash_table)> hash_table>=> HashTable(>50>)> # insert some values> hash_table.set_val(>'[email protected]'>,>'some value'>)> print>(hash_table)> print>()> hash_table.set_val(>'[email protected]'>,>'some other value'>)> print>(hash_table)> print>()> # search/access a record with key> print>(hash_table.get_val(>'[email protected]'>))> print>()> # delete or remove a value> hash_table.delete_val(>'[email protected]'>)> print>(hash_table)> |
>
>
Izhod:
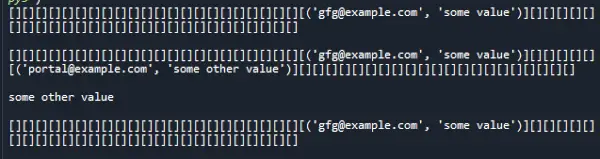
Časovna zapletenost:
Dostop do indeksa pomnilnika traja konstanten čas, zgoščevanje pa traja konstantno. Zato je kompleksnost iskanja zgoščenega zemljevida prav tako konstanten čas, to je O(1).
Prednosti HashMaps
● Hiter naključni dostop do pomnilnika prek zgoščevalnih funkcij
● Lahko uporablja negativne in neintegralne vrednosti za dostop do vrednosti.
● Ključe lahko shranite v razvrščenem vrstnem redu, zato lahko preprosto ponavljate po zemljevidih.
Slabosti HashMaps
java primerjalni niz
● Trki lahko povzročijo velike kazni in lahko povečajo časovno kompleksnost na linearno.
● Ko je število ključev veliko, ena sama zgoščevalna funkcija pogosto povzroči kolizije.
Aplikacije HashMaps
● Imajo aplikacije v izvedbah predpomnilnika, kjer so pomnilniške lokacije preslikane v majhne nize.
● Uporabljajo se za indeksiranje tulp v sistemih za upravljanje baz podatkov.
● Uporabljajo se tudi v algoritmih, kot je ujemanje vzorcev Rabina Karpa